Полносвязный слой
Коротко
Definition
Полносвязный слой — это слой нейронной сети, который выполняет линейное преобразование признаков: каждый выходной нейрон зависит от всех входных признаков.
Полносвязный слой также называют dense layer, fully connected layer или linear layer.
Главная идея: если на вход подаётся вектор признаков, слой строит новый вектор признаков как набор линейных комбинаций входных значений.
В математическом виде:
где:
- — матрица входных признаков;
- — матрица весов;
- — вектор смещений;
- — выход слоя.
Зачем нужен
Полносвязный слой нужен, чтобы смешивать признаки между собой.
Если предыдущий слой выделил признаки объекта, полносвязный слой может:
- объединить эти признаки;
- изменить размерность представления;
- подготовить признаки к классификации или регрессии;
- построить финальный выход модели.
Например, в классификаторе изображений CNN часто сначала извлекает пространственные признаки, а затем один или несколько полносвязных слоёв превращают эти признаки в вероятности классов.
Как работает
Пусть есть batch из объектов. Каждый объект имеет входных признаков.
Тогда вход можно записать как матрицу:
где:
- — число объектов в batch;
- — число входных признаков.
Если слой имеет выходных нейронов, то матрица весов имеет форму:
Вектор смещений имеет форму:
Выход слоя:
и его форма:
То есть полносвязный слой превращает каждый входной вектор длины в выходной вектор длины .
Устройство
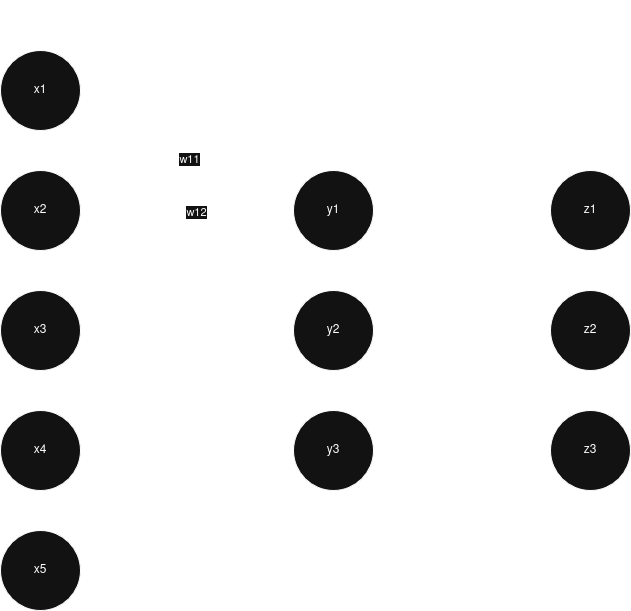
На схеме показаны два полносвязных слоя:
- Первый слой получает 5 входных признаков и выдаёт 3 выходных признака.
- Второй слой получает 3 входных признака и выдаёт 3 выходных признака.
Разберём первый слой.
Есть объектов. Каждый имеет признаков:
Есть нейрона. Каждый нейрон принимает все 5 входных признаков со своими весами. Поэтому матрица весов имеет форму:
Чтобы умножить входную матрицу на матрицу весов, в обычной записи используют транспонирование весов:
Выход становится матрицей признаков для следующего слоя.
Обучаемые параметры
У полносвязного слоя обычно есть два типа обучаемых параметров:
- матрица весов ;
- вектор смещений .
Во время обучения эти параметры изменяются с помощью обратного распространения ошибки и обновления параметров.
Если bias=False, смещение не используется, и слой выполняет только линейное преобразование:
Гиперпараметры
При создании полносвязного слоя задают:
- число входных признаков
in_features; - число выходных признаков
out_features; - использовать ли смещение
bias.
Например, слой с 5 входными признаками и 3 выходными нейронами имеет:
in_features = 5;out_features = 3;bias = TrueилиFalse.
Количество обучаемых параметров при bias=True:
Для слоя 5 → 3:
Где используется
Полносвязные слои используются:
- в классических multilayer perceptron;
- в головах классификации после CNN;
- в финальных слоях регрессионных моделей;
- в feed-forward блоках трансформеров;
- в bottleneck-представлениях автоэнкодеров;
- в небольших нейросетях для табличных данных.
Полносвязный слой особенно удобен, когда вход уже представлен как вектор фиксированной длины.
Связь с функцией активации
Строго математически полносвязный слой обычно означает только affine-преобразование:
Но в архитектурном смысле часто говорят о блоке:
где — функция активации.
Поэтому важно различать:
- линейный слой сам по себе;
- полносвязный блок как сочетание linear layer + activation.
Без нелинейных функций активации несколько полносвязных слоёв подряд всё равно сводятся к одному линейному преобразованию. Поэтому в нейросетях между полносвязными слоями обычно добавляют нелинейность.
Связанные архитектуры
Полносвязные слои встречаются в разных архитектурах:
- CNN — часто в классификационной голове;
- Трансформер — в feed-forward network внутри transformer block;
- Автоэнкодер — в encoder и decoder для векторных данных;
- GAN — в генераторе и дискриминаторе;
- Дискретный персептрон — исторически связан с идеей линейного преобразования признаков.
Полносвязные слои также часто сравнивают со свёрточными слоями. Свёрточный слой использует локальные связи и разделяемые веса, а полносвязный слой соединяет каждый входной признак с каждым выходным нейроном.
Типичные ошибки понимания
Считать полносвязный слой самостоятельной моделью
Полносвязный слой — это строительный блок. Сам по себе он обычно является частью более крупной архитектуры.
Забывать про форму матриц
Одна из частых ошибок — перепутать форму весов.
В PyTorch слой Linear(in_features, out_features) хранит веса формы:
А вычисление концептуально соответствует:
Думать, что больше нейронов всегда лучше
Увеличение out_features повышает число параметров и выразительность слоя, но также увеличивает риск переобучения и вычислительную стоимость.
Забывать про функцию активации
Один полносвязный слой без активации выполняет линейное преобразование. Несколько таких слоёв подряд без нелинейности всё равно эквивалентны одному линейному слою.
Использовать полносвязный слой там, где важна структура
Если вход — изображение, граф или длинная последовательность, простое распрямление вектора и применение полносвязного слоя может потерять важную структуру данных.
Для таких данных часто лучше использовать специальные архитектурные блоки: Свёрточный слой, Рекуррентный слой, Attention или графовые слои.
Минимальный пример
Пусть на вход подаётся один объект с 5 признаками:
Полносвязный слой должен получить 3 выходных значения:
Каждое выходное значение зависит от всех входных признаков:
Именно поэтому слой называется полносвязным: каждый выходной нейрон связан со всеми входными признаками.