Attention
Коротко
Definition
Attention — это механизм, который позволяет модели выбирать, на какие части входной последовательности нужно обратить больше внимания при построении текущего представления или предсказания.
Идея attention особенно важна для работы с последовательностями: текстом, временными рядами, аудио, биологическими последовательностями и другими данными, где разные элементы связаны друг с другом.
Главная мысль:
- не всё во входе одинаково важно;
- для каждого шага модели можно вычислить веса важности;
- затем собрать контекст как взвешенную сумму релевантных элементов.
Attention стал ключевым механизмом в Seq2Seq-моделях и основой архитектуры Трансформер.
Зачем нужен
Классические encoder-decoder модели с RNN или LSTM сжимали всю входную последовательность в один вектор состояния. Для коротких последовательностей это может работать, но для длинных возникает проблема: модель теряет детали ранних токенов.
Например, при машинном переводе длинного предложения декодеру может понадобиться обратиться к конкретному слову во входном предложении. Если вся информация сжата в один вектор, сделать это трудно.
Attention решает эту проблему: декодер не обязан помнить весь вход только через одно скрытое состояние. Он может на каждом шаге заново посмотреть на выходы энкодера и выбрать наиболее важные позиции.
Это даёт модели возможность:
- работать с длинными последовательностями;
- связывать удалённые элементы;
- строить контекст под конкретный шаг предсказания;
- интерпретировать, какие части входа были важны;
- отказаться от жёсткого bottleneck в виде одного вектора.
Как работает
В общем виде attention получает набор векторов и вычисляет, какие из них важны для текущего запроса.
Обычно используются три сущности:
- query — запрос: что мы ищем;
- key — ключ: с чем сравниваем запрос;
- value — значение: какую информацию берём, если элемент оказался важным.
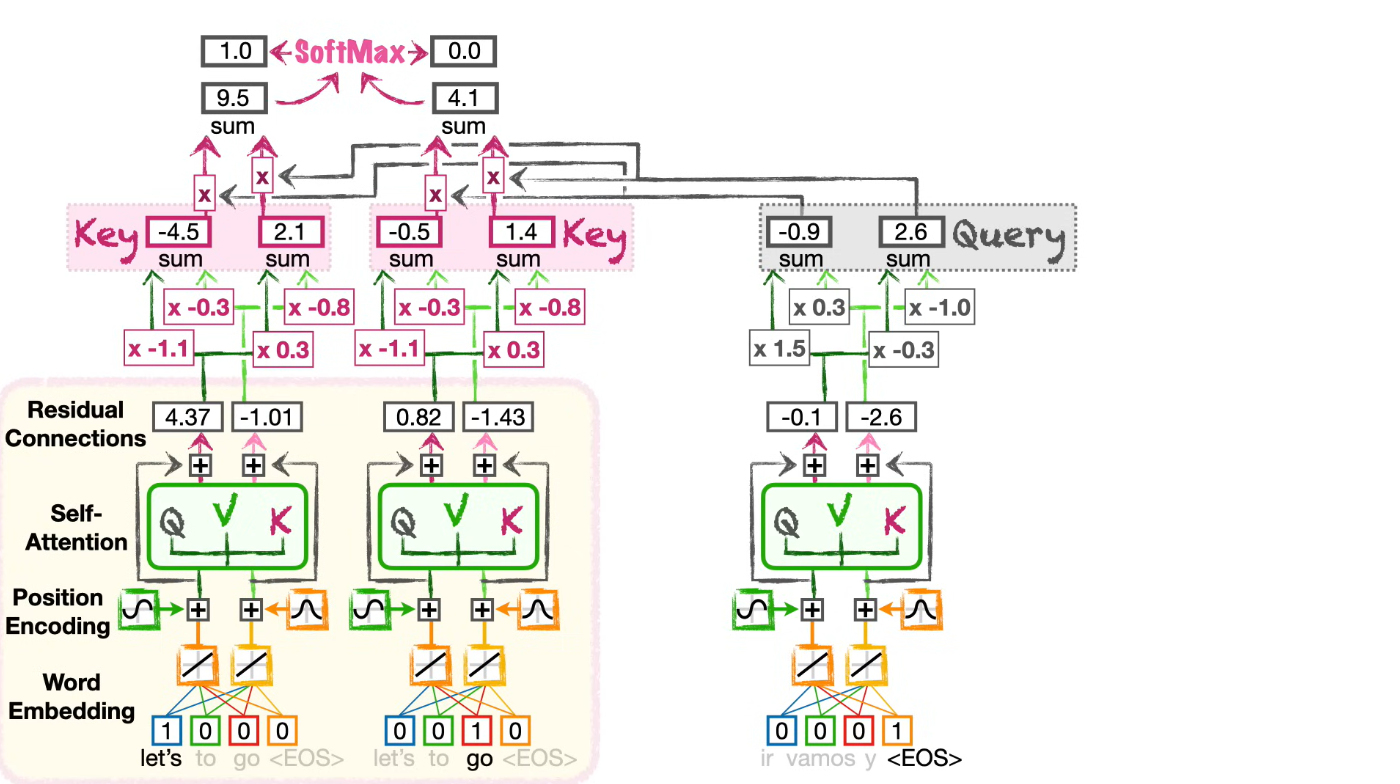
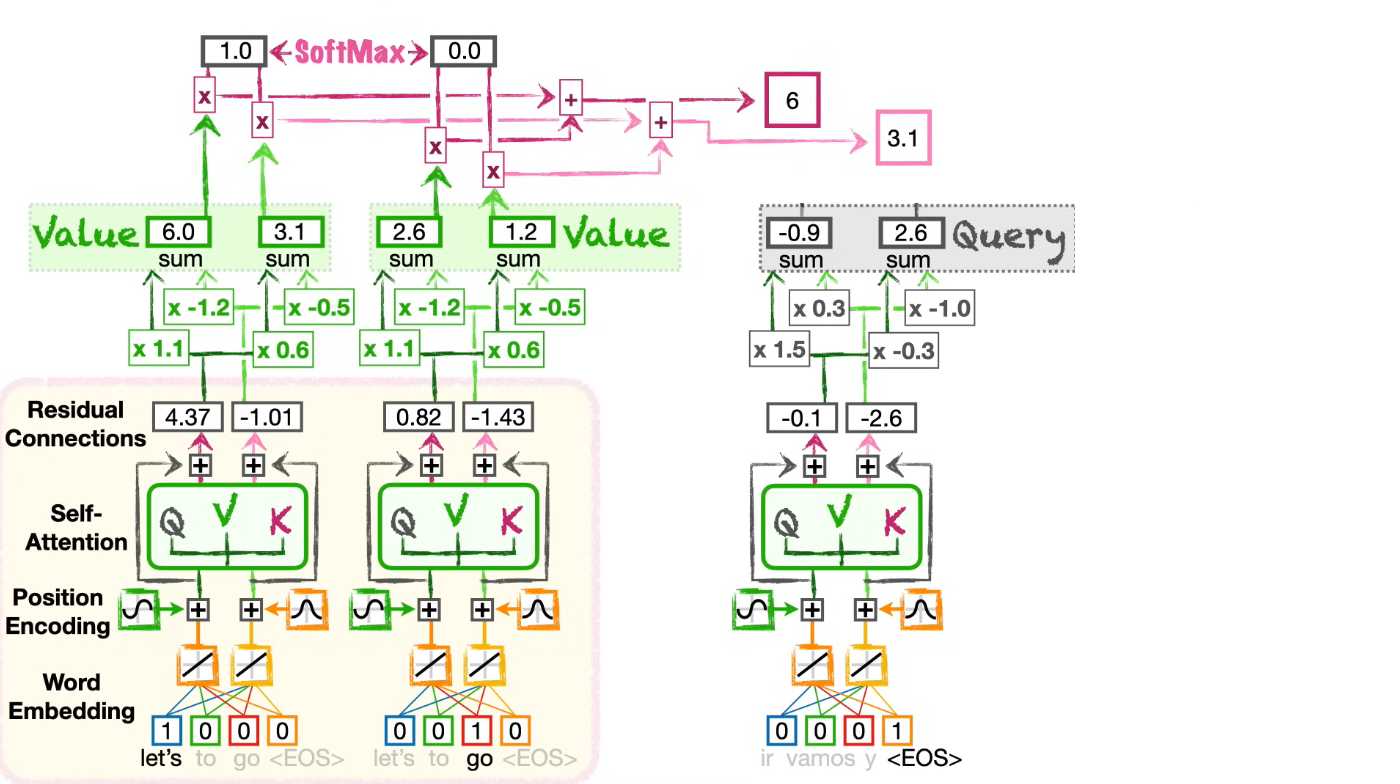
Для каждого query считается похожесть с key:
Затем scores преобразуются в веса через softmax:
После этого итоговый контекст получается как взвешенная сумма value-векторов:
В scaled dot-product attention, который используется в трансформерах, score считается через скалярное произведение:
где:
- — матрица query-векторов;
- — матрица key-векторов;
- — матрица value-векторов;
- — размерность key-векторов;
- — нормировка, которая стабилизирует значения перед softmax.
В encoder-decoder attention запросы обычно приходят из decoder, а ключи и значения — из encoder. В self-attention query, key и value строятся из одной и той же последовательности.
Где используется
Attention используется во многих архитектурах.
Основные случаи:
| Где используется | Роль attention |
|---|---|
| Seq2Seq | Помогает decoder обращаться к разным частям входной последовательности |
| Трансформер | Является центральным механизмом архитектуры |
| Машинный перевод | Связывает слова исходного и целевого предложений |
| Языковые модели | Позволяет токенам учитывать другие токены контекста |
| Vision Transformers | Позволяет patch-ам изображения взаимодействовать друг с другом |
| Speech models | Связывает аудиофрагменты и текстовые токены |
| Мультимодальные модели | Связывает текст, изображение, аудио и другие модальности |
Attention полезен там, где нужно моделировать отношения между элементами, а не просто обработать каждый элемент независимо.
Связанные архитектуры
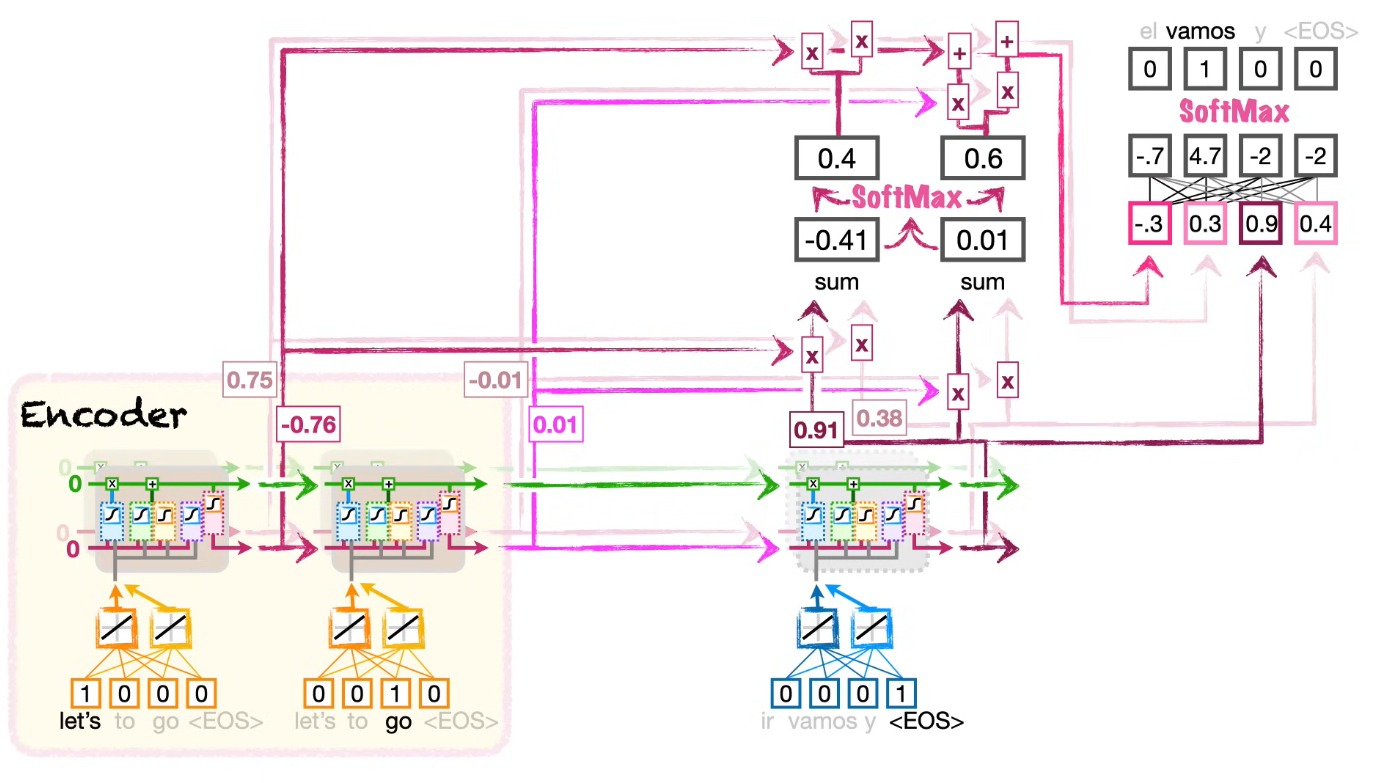
Encoder-decoder attention
В классических Seq2Seq-моделях attention помогает декодеру выбирать релевантные состояния энкодера.
На каждом шаге генерации decoder:
- имеет текущее скрытое состояние;
- сравнивает его с выходами encoder;
- получает attention-веса;
- строит контекстный вектор;
- использует его для предсказания следующего токена.
Self-attention

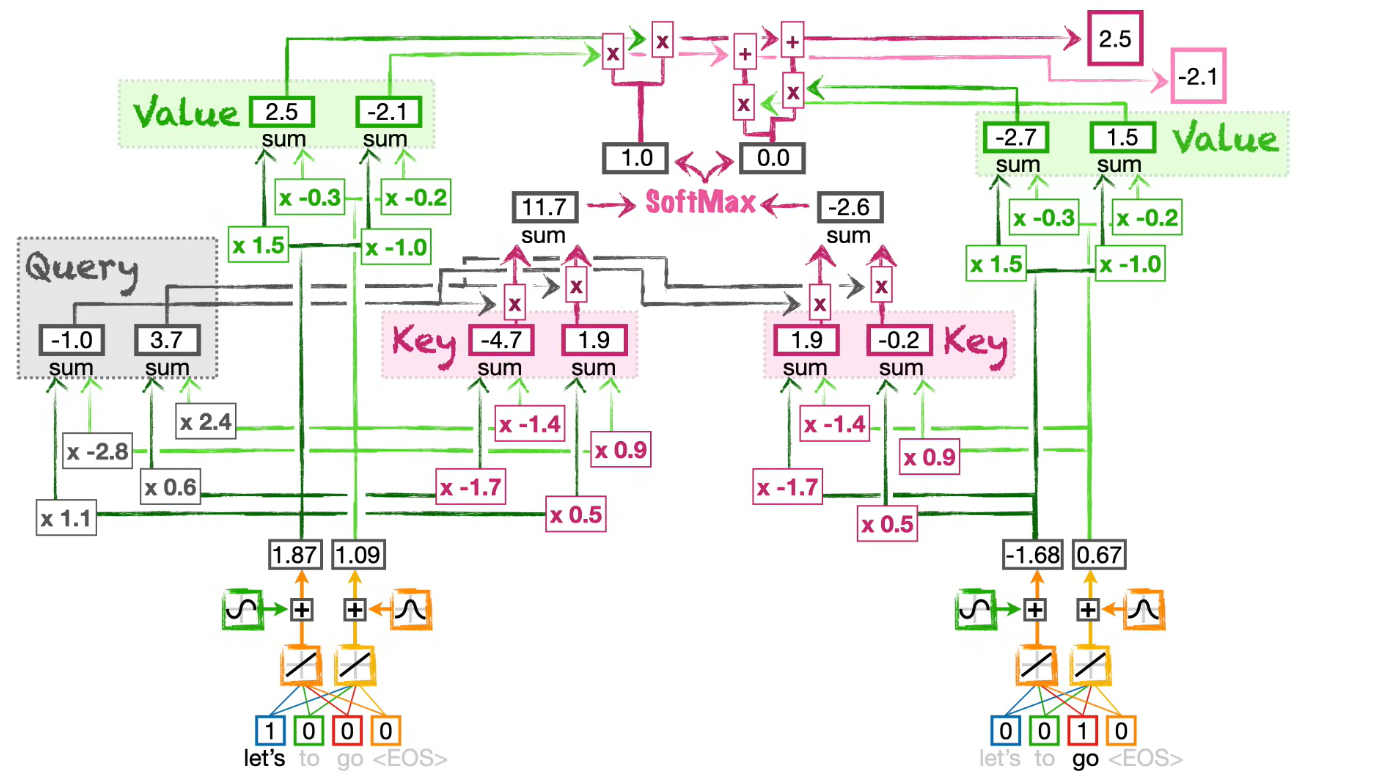
Self-attention связывает элементы одной и той же последовательности между собой.
Например, в предложении каждый токен может смотреть на другие токены и уточнять своё представление с учётом контекста.
Именно self-attention лежит в основе трансформеров.
Multi-head attention
Multi-head attention использует несколько attention-голов параллельно.
Идея:
- одна голова может отслеживать синтаксические связи;
- другая — локальный контекст;
- третья — дальние зависимости;
- итоговые представления объединяются.
Это позволяет модели учитывать разные типы отношений одновременно.
Типичные ошибки понимания
Ошибка 1. Думать, что attention — это отдельная модель
Attention — это механизм или слой, а не полноценная модель сам по себе. Он встраивается в более крупную архитектуру: Seq2Seq, трансформер, мультимодальную модель и так далее.
Ошибка 2. Считать attention-веса полноценным объяснением решения модели
Attention-веса могут подсказать, какие элементы модель использовала сильнее, но это не всегда строгая интерпретация причины ответа. Attention полезен для анализа, но не гарантирует полного объяснения.
Ошибка 3. Путать attention и self-attention
Attention — общий механизм сопоставления query, key и value. Self-attention — частный случай, когда query, key и value строятся из одной и той же последовательности.
Ошибка 4. Думать, что attention всегда заменяет память
Attention помогает обращаться к контексту, но у модели всё равно есть ограничения: длина контекста, вычислительная сложность, качество обученных представлений.
Ошибка 5. Игнорировать вычислительную стоимость
Self-attention обычно имеет квадратичную сложность по длине последовательности:
Это может быть проблемой для очень длинных документов, аудио или видео.
Минимальный пример
import torch
import torch.nn.functional as F
Q = torch.randn(2, 4)
K = torch.randn(5, 4)
V = torch.randn(5, 3)
scores = Q @ K.T / (K.shape[-1] ** 0.5)
weights = F.softmax(scores, dim=-1)
context = weights @ V
print(weights.shape)
print(context.shape)В этом примере:
Qсодержит 2 query-вектора;Kсодержит 5 key-векторов;Vсодержит 5 value-векторов;weightsпоказывает, насколько каждый query связан с каждым key;contextсодержит итоговые контекстные представления.