Обновление параметров
Коротко
Definition
Обновление параметров — это шаг обучения модели, на котором веса изменяются в направлении, уменьшающем функцию потерь.
В нейронных сетях параметры обычно обновляются после вычисления градиентов через обратное распространение ошибки.
Главная идея:
Если модель имеет параметры , а функция потерь равна , то оптимизатор должен изменить так, чтобы loss стал меньше.
Интуиция
Функция потерь показывает, насколько плохо модель решает задачу.
Если представить loss как поверхность, то обучение похоже на движение вниз по этой поверхности. Градиент показывает направление самого быстрого роста функции. Чтобы уменьшить loss, нужно идти в противоположную сторону — по антиградиенту.
Базовое правило:
где:
- — параметры на шаге ;
- — градиент loss по параметрам;
- — learning rate;
- — параметры после обновления.
Learning rate задаёт размер шага. Если он слишком маленький, обучение идёт медленно. Если слишком большой, модель может перескакивать минимум или расходиться.
Функция потерь и градиент
Для датасета из объектов функционал потерь можно записать так:
где:
- — входной объект;
- — правильный ответ;
- — параметры модели;
- — ошибка на одном объекте.
Градиент функционала потерь по весам:
На практике часто используют не весь датасет, а mini-batch. Тогда градиент считается приближённо, по части объектов. Это быстрее, но делает направление обновления шумным.
Базовое обновление
Для минимизации функции базовый gradient descent использует правило:
Знак минус важен: градиент показывает направление роста функции, а нам нужно уменьшать loss.
Для нейронной сети аналогично:
Это базовая идея, но в реальных задачах простого градиентного спуска часто недостаточно.
Основные проблемы
При обновлении параметров возникают несколько типичных проблем.
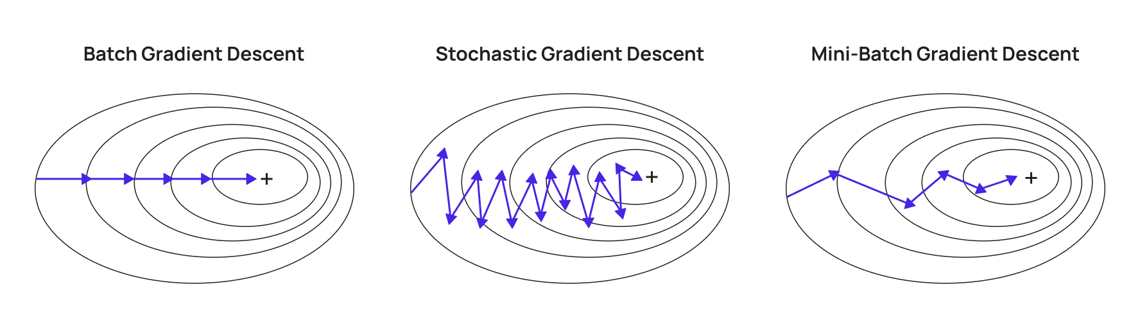
Шумное направление градиента
При mini-batch training градиент считается не по всему датасету, а по небольшой части объектов. Поэтому направление может быть шумным и нестабильным.
Модель может двигаться к минимуму зигзагообразно.
Плохие стационарные точки
Оптимизация может замедляться около седловых точек или плоских областей.
В таких местах градиент мал или направление движения плохо помогает быстро выйти из области.
Разный масштаб градиентов
У разных параметров масштаб градиентов может сильно отличаться.
Одни параметры требуют маленьких шагов, другие — больших. Если использовать один общий learning rate для всех параметров, обучение может быть медленным или нестабильным.
Затухание и взрыв градиентов
В глубоких сетях градиенты могут становиться слишком маленькими или слишком большими.
Малые градиенты связаны с затуханием градиента. Большие градиенты могут приводить к нестабильным обновлениям и расходимости.
Momentum
Momentum, или инерция, решает проблему нестабильного направления градиента и помогает проходить плохие стационарные области.
Идея: обновление зависит не только от текущего градиента, но и от накопленной скорости движения.
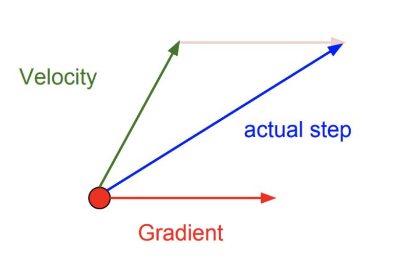
Скорость:
где:
- — накопленный импульс;
- — коэффициент momentum;
- — текущий градиент.
Обновление параметров:
Интуитивно:
- если градиенты много шагов направлены примерно одинаково, momentum ускоряет движение;
- если градиенты шумят в разные стороны, momentum сглаживает зигзаги.
Условно: новая скорость — это смесь старой скорости и нового градиента.
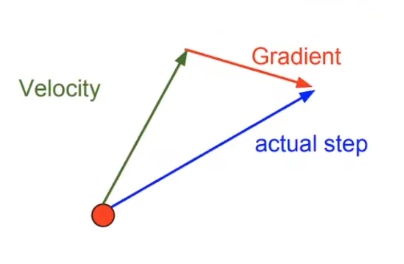
Nesterov momentum
Nesterov accelerated gradient улучшает обычный momentum.
Идея: сначала сделать мысленный шаг по инерции, посмотреть градиент в будущей точке, а затем скорректировать движение.
Формула:
Отличие от обычного momentum:
- momentum смотрит градиент в текущей точке;
- Nesterov смотрит градиент в точке, куда уже ведёт инерция.
Это можно понимать как более осторожное и «заглядывающее вперёд» обновление.
AdaGrad
AdaGrad адаптирует learning rate для каждого параметра отдельно.
Он решает проблему разного масштаба градиентов: параметры с большими накопленными градиентами получают меньшие шаги, а параметры с маленькими накопленными градиентами — относительно большие.
Накопление квадратов градиентов:
Обновление:
где:
- — накопленная сумма квадратов градиентов;
- — маленькая константа для численной устойчивости.
Интуиция:
- крутой спуск — идти осторожнее;
- пологая область — можно идти относительно быстрее.
Проблема AdaGrad: монотонно растёт. Из-за этого effective learning rate может стать слишком маленьким, и обучение почти остановится.
RMSProp
RMSProp решает проблему AdaGrad, заменяя бесконечное накопление квадратов градиентов на экспоненциальное скользящее среднее.
Кеш квадратов градиентов:
Обновление:
Здесь старые градиенты постепенно забываются. Поэтому learning rate не затухает так резко, как в AdaGrad.
RMSProp особенно полезен, когда масштаб градиентов меняется во время обучения.
Adam
Adam объединяет две идеи:
- Momentum — накопление среднего градиента.
- RMSProp — адаптацию шага через средний квадрат градиента.
Первый момент, похожий на momentum:
Второй момент, похожий на RMSProp:
Упрощённое обновление:
В полной версии Adam также использует bias correction для и , потому что в начале обучения эти оценки смещены к нулю.
Adam часто является хорошим default-оптимизатором для нейросетей, но не всегда даёт лучшую обобщающую способность по сравнению с SGD + momentum.
AdamW и weight decay
Weight decay — это способ регуляризации параметров, при котором большие веса штрафуются и постепенно уменьшаются.
Классическая L2-регуляризация добавляет штраф к loss:
Weight decay можно понимать как дополнительное уменьшение весов при обновлении:
Интуиция: веса не должны бесконтрольно расти.
AdamW — вариант Adam, где weight decay отделён от градиентной части обновления. Это часто работает лучше, чем наивное добавление L2-регуляризации в Adam.
Weight decay связан с регуляризацией.
Как выбирать оптимизатор
Простые ориентиры:
- SGD — базовый и понятный оптимизатор, но может требовать аккуратного learning rate schedule.
- SGD + momentum — сильный вариант для многих задач компьютерного зрения.
- RMSProp — полезен при нестабильных и меняющихся масштабах градиентов.
- Adam — хороший default для многих нейросетевых задач.
- AdamW — часто используется в современных deep learning моделях, включая transformer-based архитектуры.
На практике качество зависит не только от оптимизатора, но и от:
- learning rate;
- batch size;
- инициализации;
- нормализации;
- архитектуры;
- регуляризации;
- данных.
Связь с learning rate
Learning rate — один из самых важных гиперпараметров обновления.
Если learning rate слишком большой:
- loss может прыгать;
- обучение может расходиться;
- модель может перескакивать хорошие решения.
Если learning rate слишком маленький:
- обучение идёт медленно;
- модель может застрять;
- прогресс почти незаметен.
Поэтому часто используют не постоянный learning rate, а schedule. Подробнее см. Изменение скорости обучения.
Минимальный пример
Пусть есть один параметр , градиент , learning rate .
Обычное обновление gradient descent:
Подставим значения:
Параметр уменьшился, потому что положительный градиент означает: при увеличении функция растёт, значит для уменьшения функции нужно двигаться в сторону меньшего .
Если градиент отрицательный, обновление пойдёт в другую сторону.
Типичные ошибки понимания
Путать градиент и антиградиент
Градиент показывает направление роста функции. Для минимизации нужно идти в противоположную сторону.
Поэтому в базовой формуле стоит минус:
Думать, что Adam всегда лучший
Adam часто хорошо работает из коробки, но не всегда даёт лучший результат. В некоторых задачах SGD + momentum может обобщаться лучше.
Игнорировать learning rate
Даже хороший оптимизатор может работать плохо при неправильном learning rate.
Забывать про bias correction в Adam
Упрощённая формула Adam полезна для интуиции, но полная версия включает коррекцию смещения первого и второго моментов.
Смешивать weight decay и L2 без нюансов
Для SGD L2-регуляризация и weight decay часто выглядят очень похоже. Для адаптивных оптимизаторов вроде Adam различие важнее, поэтому часто используют AdamW.