Автоэнкодер
Коротко
Definition
Автоэнкодер — это нейросетевая архитектура, которая учится сжимать входные данные в скрытое представление, а затем восстанавливать исходный объект из этого представления.
Автоэнкодер состоит из двух основных частей:
- encoder — сжимает вход в латентный вектор ;
- decoder — восстанавливает объект из латентного вектора .
Схематично:
где:
- — исходный объект;
- — скрытое, или латентное, представление;
- — восстановленный объект.
Главная идея: если модель научилась хорошо восстанавливать объект через узкое скрытое представление, значит она выучила важные признаки данных.
Интуиция
Автоэнкодер можно представить как систему сжатия.
Encoder пытается сохранить в только самую важную информацию об объекте. Decoder пытается по этому сжатому описанию восстановить исходный объект.
Если скрытое пространство слишком маленькое или ограниченное, модель вынуждена учиться выделять существенные признаки, а не просто копировать вход.
Например:
- для изображений latent vector может хранить форму, цвет, стиль и положение объектов;
- для табличных данных — основные факторы вариации;
- для сигналов — сжатое описание паттерна;
- для молекул — признаки структуры, если модель построена под такие данные.
Формальное описание
Классический автоэнкодер можно записать как композицию двух функций.
Encoder:
Decoder:
Итоговое восстановление:
где:
- — encoder с параметрами ;
- — decoder с параметрами ;
- — латентное представление;
- — реконструкция входа.
Автоэнкодер обычно относят к representation learning и unsupervised или self-supervised learning: модель учится по самим входным данным, используя как целевой ответ для восстановления.
Входы и выходы
Вход зависит от типа данных:
- Изображения — tensor пикселей;
- Табличные данные — вектор признаков;
- Последовательности — токены, сигналы или временные ряды;
- Графовые данные — графовые структуры, если используется графовый автоэнкодер.
Выход классического автоэнкодера имеет тот же тип и форму, что и вход:
Например:
- вход — изображение
64 × 64 × 3; - выход — восстановленное изображение
64 × 64 × 3.
Латентный вектор обычно имеет меньшую размерность или более ограниченную структуру, чем исходный объект.
Устройство
Три основных компонента автоэнкодера:
- Encoder.
- Latent space.
- Decoder.
Encoder
Encoder преобразует входные данные в скрытое представление :
Задача encoder — извлечь компактное представление объекта.
Для изображений encoder может быть CNN. Для последовательностей — LSTM, Трансформер или другая sequence-модель. Для табличных данных — полносвязная сеть.
Latent space
Latent space — это пространство скрытых представлений.
Вектор должен содержать информацию, достаточную для восстановления объекта, но желательно без лишнего шума.
Если latent space хорошо организован, похожие объекты получают похожие представления.
Decoder
Decoder восстанавливает объект из латентного вектора:
Задача decoder — по сжатому описанию построить объект, похожий на исходный.
В простом автоэнкодере decoder учится реконструировать вход. В генеративных вариантах decoder также может использоваться для создания новых объектов.
Как обучается
Классический автоэнкодер обучается минимизировать ошибку восстановления между входом и выходом.
Общий вид:
Для числовых данных часто используют MSE:
или:
Для бинарных данных или нормализованных изображений могут использовать binary cross-entropy или другие reconstruction losses.
Обучение происходит через Обратное распространение ошибки и Обновление параметров.
Функция потерь
Для обычного автоэнкодера основная функция потерь — reconstruction loss.
Она измеряет, насколько хорошо модель восстановила вход.
Примеры:
| Тип данных | Частая функция потерь |
|---|---|
| Непрерывные признаки | MSE |
| Бинарные признаки | Binary cross-entropy |
| Изображения | MSE, MAE, perceptual loss |
| Последовательности | Cross-entropy по токенам |
Важно: низкая ошибка восстановления не всегда означает хорошее latent space. Модель может научиться копировать вход, особенно если latent dimension слишком большая.
Зачем нужен
Автоэнкодеры используют для разных задач:
- сжатие данных;
- извлечение признаков;
- representation learning;
- denoising;
- anomaly detection;
- предобучение;
- генерация данных в специальных вариантах;
- визуализация скрытых структур;
- поиск похожих объектов в latent space.
Например, если автоэнкодер обучен восстанавливать нормальные объекты, то аномальные объекты могут восстанавливаться плохо. Тогда reconstruction error можно использовать как сигнал аномалии.
Проблема генерации в обычном автоэнкодере
Warning
У классического автоэнкодера скрытое пространство специально не регуляризуется. Поэтому decoder нельзя надёжно использовать для генерации новых валидных объектов из случайных latent vectors.
Проблема в том, что encoder может разложить объекты в latent space как угодно:
- кластеры могут быть далеко друг от друга;
- между кластерами могут быть пустые области;
- случайная точка может не соответствовать ни одному осмысленному объекту;
- интерполяция между объектами может давать бессмысленные результаты.
Обычный автоэнкодер хорошо восстанавливает объекты, которые прошли через encoder. Но если взять случайный latent vector и подать в decoder, результат может быть невалидным.
Именно поэтому для генерации используют специальные варианты, например VAE или VQ-VAE.
Вариационный автоэнкодер
Вариационный автоэнкодер, или VAE, — это генеративная модификация автоэнкодера.
Definition
VAE — это автоэнкодер, который кодирует объект не в одну точку latent space, а в параметры вероятностного распределения, из которого затем сэмплируется latent vector.
В обычном автоэнкодере:
В VAE:
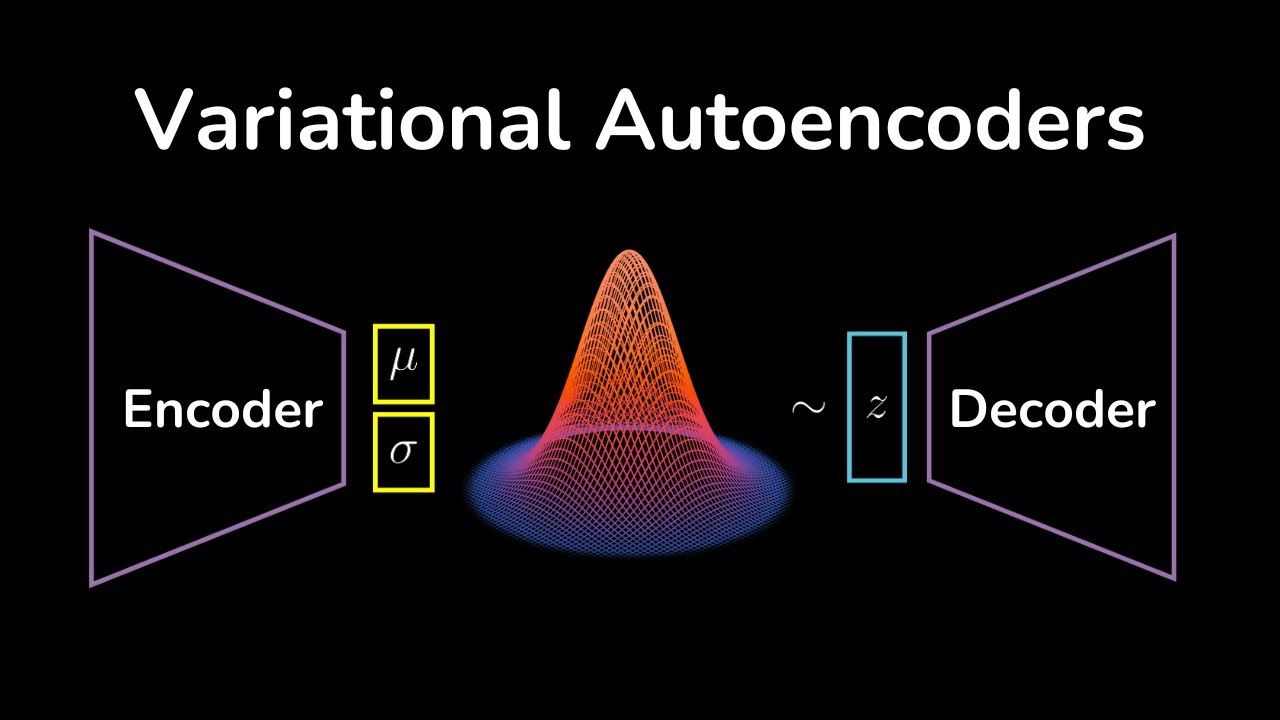
Главная идея VAE: сделать latent space непрерывным, регуляризованным и пригодным для генерации.
Устройство VAE
VAE состоит из тех же крупных частей, что и автоэнкодер, но encoder работает иначе.
Encoder
Encoder преобразует вход не в один latent vector, а в параметры распределения:
Обычно предполагается нормальное распределение:
То есть encoder говорит не «этот объект находится строго в точке », а «этот объект соответствует облаку вероятных точек в latent space».
Пример из старой заметки:
- входной объект — RGB-вектор фиолетового цвета ;
- latent space — двумерный;
- encoder выдаёт ;
- encoder выдаёт .
Это можно понимать так: модель считает, что фиолетовый цвет находится где-то в правой нижней части latent map, но есть неопределённость.
Reparameterization trick
Чтобы обучать VAE через backpropagation, нужно сэмплировать так, чтобы случайность не ломала вычислительный граф.
Для этого используют reparameterization trick:
где:
- — случайный шум;
- и — параметры, предсказанные encoder;
- — поэлементное умножение.
Important
Случайность выносится в , а и остаются дифференцируемыми. Поэтому через них можно передавать градиент.
Пример:
- ;
- ;
- .
Тогда:
Получаем:
Decoder
Decoder получает сэмплированный latent vector и восстанавливает объект:
Например, если decoder получил , он может попытаться восстановить RGB-вектор фиолетового цвета:
Функция потерь VAE
VAE обучается через ELBO — evidence lower bound. На практике часто минимизируют отрицание ELBO.
Типичный loss VAE состоит из двух частей:
Первая часть — reconstruction loss. Она заставляет decoder хорошо восстанавливать объект.
Вторая часть — KL-divergence. Она заставляет распределение быть близким к prior, обычно:
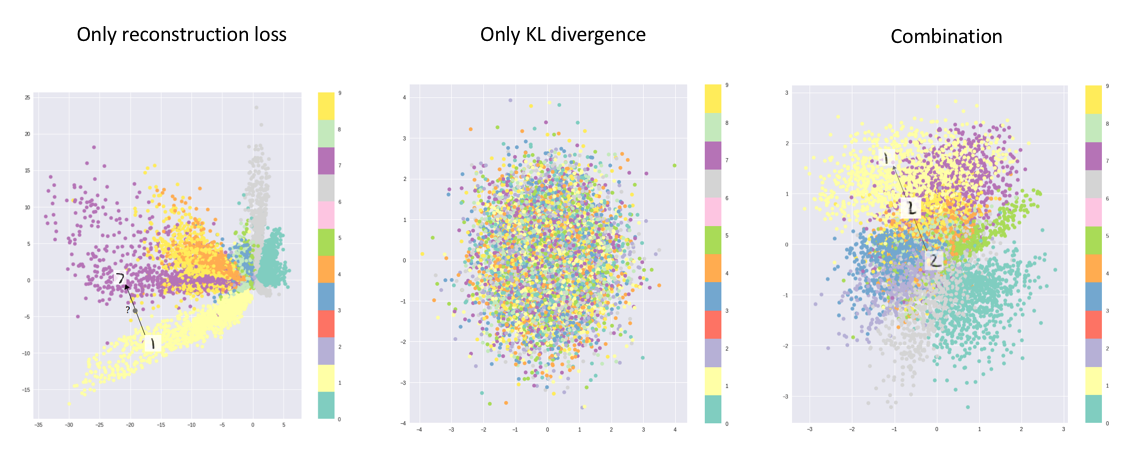
Интуитивно в VAE происходит «перетягивание каната»:
- Reconstruction loss говорит: раздвинь разные объекты подальше, чтобы decoder не путался.
- KL-divergence говорит: держи latent distributions ближе к нормальному prior и не создавай пустые разрывы.
Компромисс приводит к более гладкому latent space, где случайные точки чаще декодируются в осмысленные объекты.
KL-дивергенция в VAE
KL-дивергенция измеряет отличие предсказанного распределения latent vector от эталонного нормального распределения.
Для нормального prior KL-часть штрафует:
- слишком далёкие от нуля центры ;
- слишком маленькие или слишком большие дисперсии;
- слишком нерегулярное latent space.
Для одного измерения часто используется выражение вида:
Пример из старой заметки:
- исходный ;
- восстановление ;
- reconstruction loss маленький: примерно ;
- но далеко от нуля;
- KL штрафует модель за то, что latent cloud ушёл далеко от prior.
Итог: модель может немного пожертвовать точностью восстановления, чтобы latent space стал более регулярным и пригодным для генерации.
Интерактивный пример для интуиции latent space: https://tayden.github.io/VAE-Latent-Space-Explorer/
Условный VAE
CVAE, или conditional variational autoencoder, — это управляемая версия VAE.
Definition
CVAE — это VAE, в котором генерация дополнительно зависит от условия : класса, свойства или другого контролируемого признака.
В обычном VAE мы сэмплируем случайную точку из latent space и заранее не знаем, что получится.
В CVAE decoder получает не только latent vector , но и условие :
Encoder тоже может получать условие:
Условием может быть:
- класс изображения;
- желаемое свойство объекта;
- метка стиля;
- химическое свойство;
- категория текста.
Пример: при генерации молекул можно задать условие «низкая токсичность» или «высокая растворимость». Шум отвечает за разнообразие, а условие направляет генерацию.
VQ-VAE
VQ-VAE, или Vector Quantized VAE, заменяет непрерывное latent space на дискретный словарь кодов.
Definition
VQ-VAE — это вариант автоэнкодера, в котором encoder выдаёт вектор, затем он заменяется ближайшим вектором из обучаемого codebook, а decoder восстанавливает объект по этому дискретному коду.
Главная идея:
где:
- — выход encoder;
- — ближайший codebook vector;
- codebook — набор обучаемых дискретных embedding-векторов.
VQ-VAE решает часть проблем обычных VAE:
- уменьшает размытость реконструкций;
- делает latent representation дискретным;
- позволяет кодировать данные как последовательность дискретных токенов;
- хорошо подходит для данных с дискретной структурой.
VQ-VAE полезен для:
- изображений;
- аудио;
- речи;
- дискретных последовательностей;
- токенизации сложных объектов для последующей обработки трансформерами.
В старой заметке это было сформулировано так: VQ-VAE превращает сложные данные в последовательность кодов, которую затем можно эффективно обрабатывать трансформерами.
Гиперпараметры
Основные гиперпараметры автоэнкодеров:
- размер latent space;
- архитектура encoder;
- архитектура decoder;
- reconstruction loss;
- learning rate;
- batch size;
- число эпох;
- регуляризация;
- уровень шума для denoising autoencoder;
- вес KL-члена для VAE;
- размер codebook для VQ-VAE;
- размер embedding-векторов в VQ-VAE.
Для VAE часто вводят коэффициент при KL-члене:
Такой вариант называют -VAE.
Большая сильнее регуляризует latent space, но может ухудшить качество реконструкции.
Когда использовать
Автоэнкодер стоит использовать, если:
- нужно выучить скрытое представление данных;
- нужно сжать данные;
- нужно очистить данные от шума;
- нужно искать аномалии по reconstruction error;
- нужно предобучить representation;
- нужно получить generative model через VAE/VQ-VAE;
- нужно изучить latent space.
Классический автоэнкодер хорошо подходит для representation learning и reconstruction. VAE лучше подходит для генерации новых объектов. VQ-VAE полезен, когда нужно дискретное latent representation.
Когда не использовать
Автоэнкодер может быть плохим выбором, если:
- нужна простая интерпретируемая модель;
- данных мало, а модель большая;
- reconstruction objective не связан с целевой задачей;
- нужен гарантированно хороший генератор, но используется обычный AE;
- latent space не анализируется и не используется;
- задача лучше решается supervised-моделью.
Важно: хорошая reconstruction loss не всегда означает полезное представление для downstream-задачи.
Метрики оценки
Метрики зависят от цели.
Для reconstruction:
- MSE;
- MAE;
- binary cross-entropy;
- perceptual similarity для изображений.
Для anomaly detection:
- ROC-AUC;
- precision/recall;
- threshold по reconstruction error.
Для генерации:
- качество сэмплов;
- diversity;
- FID для изображений;
- domain-specific metrics.
Для representation learning:
- качество downstream-модели;
- кластеризация в latent space;
- визуализация через PCA, t-SNE или UMAP.
Типичные ошибки понимания
Думать, что любой автоэнкодер является хорошей генеративной моделью
Классический автоэнкодер не обязан иметь гладкое latent space. Случайные точки в latent space могут декодироваться в мусор.
Для генерации обычно используют VAE, VQ-VAE, GAN, диффузионные модели или другие специальные подходы.
Слишком большой latent space
Если latent space слишком большой, модель может просто научиться копировать вход, не выделяя полезные признаки.
Оценивать только reconstruction loss
Низкая ошибка восстановления не гарантирует, что latent representation полезен для классификации, кластеризации или генерации.
Путать VAE и обычный AE
Обычный AE кодирует объект в точку. VAE кодирует объект в распределение и добавляет KL-регуляризацию.
Забывать про reparameterization trick
Без reparameterization trick сэмплирование из распределения мешало бы обучению через backpropagation.
Считать, что KL-divergence просто ухудшает reconstruction
KL действительно может ухудшить точность восстановления, но он нужен, чтобы latent space был регулярным и пригодным для генерации.
Минимальный пример
Допустим, есть простой RGB-вектор:
Обычный автоэнкодер:
- Encoder сжимает его в latent vector:
- Decoder восстанавливает:
- Reconstruction loss сравнивает:
и
Если использовать MSE, ошибка по каналам:
| Канал | Исходное значение | Восстановление | Квадрат ошибки |
|---|---|---|---|
| R | 0.8 | 0.75 | 0.0025 |
| G | 0.2 | 0.30 | 0.0100 |
| B | 0.9 | 0.85 | 0.0025 |
Суммарная ошибка:
VAE добавил бы к такой ошибке ещё KL-штраф за устройство latent distribution.
Практические замечания
Хороший workflow:
- Определить цель: reconstruction, anomaly detection, generation или representation learning.
- Выбрать архитектуру encoder и decoder под тип данных.
- Выбрать размер latent space.
- Обучить простой автоэнкодер как baseline.
- Проверить reconstruction examples, а не только loss.
- Если нужна генерация, использовать VAE/VQ-VAE, а не обычный AE.
- Анализировать latent space.
- Проверить downstream-качество, если representation используется дальше.
- Следить за переобучением.
- Сравнить с альтернативами: PCA, supervised-модель, GAN, Диффузионная модель.
Для изображений важно смотреть восстановленные примеры визуально. Для табличных данных важно проверять, какие признаки восстанавливаются плохо.