Изменение скорости обучения
Коротко
Definition
Изменение скорости обучения — это приём оптимизации, при котором learning rate меняется во время обучения модели, чтобы сначала быстро искать хорошую область параметров, а затем аккуратно сходиться к более качественному решению.
Learning rate определяет размер шага при обновлении параметров.
Базовое обновление:
где — скорость обучения.
Если слишком большая, модель может нестабильно прыгать вокруг минимума. Если слишком маленькая, обучение будет медленным. Поэтому на практике learning rate часто меняют по расписанию.
Интуиция
При стохастическом градиентном спуске траектория обучения шумная. Градиент считается по mini-batch, поэтому направление обновления не идеально указывает к минимуму.
В начале обучения модель обычно далека от хорошего решения, поэтому можно использовать более крупные шаги. Это помогает быстрее исследовать пространство параметров.
Ближе к концу обучения крупный шаг может мешать: модель начинает прыгать вокруг хорошего решения и не может аккуратно подстроить параметры. Тогда learning rate уменьшают.
Общая идея:
- в начале — большой шаг для быстрого движения;
- в середине — постепенное уточнение;
- в конце — маленький шаг для более точной сходимости.
Зачем нужно менять learning rate
Изменение learning rate помогает:
- ускорить обучение;
- уменьшить колебания около минимума;
- улучшить финальное качество;
- избежать слишком раннего застревания;
- стабилизировать обучение;
- сделать обучение глубоких сетей более управляемым.
Learning rate schedule особенно важен для глубоких нейросетей, где качество сильно зависит не только от архитектуры, но и от режима оптимизации.
Основные стратегии
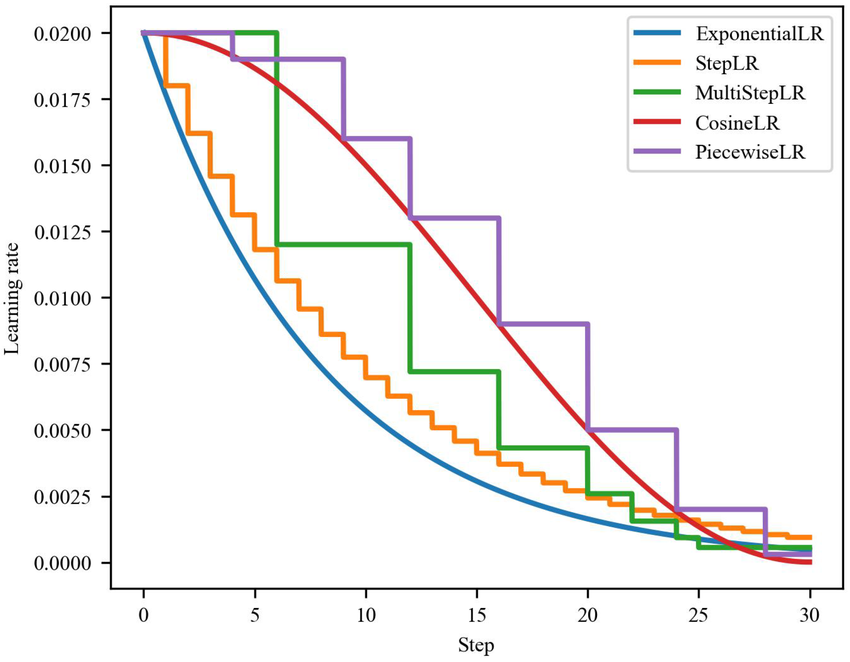
Step Decay
Step Decay — простая стратегия, при которой learning rate уменьшается в несколько раз через заданные интервалы.
Например:
| Эпохи | Learning rate |
|---|---|
| 1–30 | 0.1 |
| 31–60 | 0.01 |
| 61–90 | 0.001 |
Идея: долго обучаться с одним шагом, затем резко уменьшить его.
Формально:
где:
- — начальный learning rate;
- — коэффициент уменьшения;
- — период между снижениями;
- — номер эпохи или шага.
Step Decay прост и часто работает хорошо, но требует заранее выбрать моменты снижения.
Exponential Decay
Exponential Decay плавно уменьшает learning rate по экспоненциальному закону.
Один из вариантов:
где:
- — начальный learning rate;
- — скорость затухания;
- — номер шага или эпохи.
В отличие от Step Decay, learning rate уменьшается не скачками, а плавно.
Cosine Annealing
Cosine Annealing плавно изменяет learning rate по косинусной кривой.
Типичная формула:
где:
- — начальное или максимальное значение;
- — минимальное значение;
- — длительность расписания;
- — текущий шаг.
Идея:
- в начале learning rate высокий;
- затем он плавно снижается;
- к концу обучения становится очень маленьким.
Cosine Annealing популярен, потому что даёт плавное снижение без резких скачков.
Warmup
Warmup — стратегия, при которой learning rate сначала не уменьшают, а наоборот постепенно увеличивают от маленького значения до рабочего.
Это полезно в начале обучения, когда веса ещё случайны, а большие обновления могут сделать обучение нестабильным.
Пример линейного warmup:
для первых шагов.
Warmup часто используют в трансформерах и больших нейросетях.
Warmup + decay
На практике часто объединяют warmup и дальнейшее снижение learning rate.
Типичная схема:
- Небольшой learning rate в начале.
- Постепенное увеличение во время warmup.
- Плавное снижение через cosine decay, linear decay или другую стратегию.
Это особенно часто встречается в современных deep learning pipeline.
ReduceLROnPlateau
ReduceLROnPlateau уменьшает learning rate не по заранее заданному расписанию, а когда метрика перестаёт улучшаться.
Например:
- validation loss не уменьшается несколько эпох;
- validation accuracy не растёт;
- модель вышла на plateau.
Тогда learning rate уменьшается, например, в 2 или 10 раз.
Эта стратегия удобна, когда заранее неизвестно, на каких эпохах нужно снижать learning rate.
Адаптивные методы
Существуют оптимизаторы, которые не просто меняют общий learning rate, а адаптируют шаг отдельно для разных параметров.
Примеры:
- AdaGrad;
- RMSProp;
- Adam;
- AdamW.
Они описаны в заметке Обновление параметров.
Важно: адаптивный оптимизатор не отменяет общий learning rate. Даже для Adam или AdamW выбор learning rate и schedule всё равно сильно влияет на качество обучения.
Например, AdamW часто используют вместе с warmup и cosine decay.
Когда использовать
Learning rate schedule полезен почти всегда при обучении нейронных сетей.
Особенно он важен, если:
- модель глубокая;
- обучение долгое;
- loss нестабильно колеблется;
- модель перестала улучшаться;
- используется SGD или SGD + momentum;
- нужно выжать лучшее качество;
- обучается CNN, Трансформер или другая глубокая архитектура.
В простых учебных задачах можно начать с постоянного learning rate. Но в серьёзных экспериментах schedule почти всегда стоит рассматривать.
Когда не использовать
Изменение learning rate может быть избыточным, если:
- модель очень простая;
- обучение занимает несколько секунд;
- задача демонстрационная;
- используется готовая модель и меняется только маленькая голова;
- качество не чувствительно к learning rate.
Но даже в таких случаях полезно понимать, что плохой learning rate может испортить обучение сильнее, чем выбор модели.
Минимальный пример
Допустим, модель обучается 90 эпох.
Можно использовать Step Decay:
| Эпохи | Learning rate |
|---|---|
| 1–30 | 0.1 |
| 31–60 | 0.01 |
| 61–90 | 0.001 |
Интерпретация:
- первые 30 эпох модель быстро ищет хорошую область;
- следующие 30 эпох уточняет решение;
- последние 30 эпох делает маленькие шаги и стабилизирует веса.
Если validation loss после 30 эпох начинает прыгать вокруг одного уровня, снижение learning rate может помочь модели аккуратнее сойтись.
Практические замечания
Хороший порядок работы:
- Выбрать оптимизатор.
- Подобрать разумный начальный learning rate.
- Посмотреть train loss и validation loss.
- Если обучение нестабильно — уменьшить learning rate.
- Если обучение слишком медленное — попробовать увеличить learning rate.
- Добавить schedule: Step Decay, Cosine Annealing или ReduceLROnPlateau.
- Для больших моделей рассмотреть warmup.
- Сравнивать настройки по validation, а не по test.
Важно смотреть не только финальную метрику, но и кривые обучения. Они часто показывают, слишком большой или слишком маленький learning rate.
Типичные ошибки понимания
Думать, что schedule исправит любой плохой learning rate
Если начальный learning rate совсем неудачный, расписание может не помочь. Сначала нужно подобрать разумный диапазон значений.
Снижать learning rate слишком рано
Если learning rate уменьшить слишком рано, модель может не успеть выйти из плохой области и будет обучаться медленно.
Снижать learning rate слишком поздно
Если долго держать слишком большой learning rate, модель может колебаться около хорошего решения и не улучшаться.
Путать adaptive optimizer и schedule
Adam адаптирует шаги по параметрам, но общий learning rate всё равно остаётся важным гиперпараметром.
Подбирать schedule по test-выборке
Learning rate schedule нужно выбирать по train/validation. Test должен оставаться для финальной оценки.