CNN
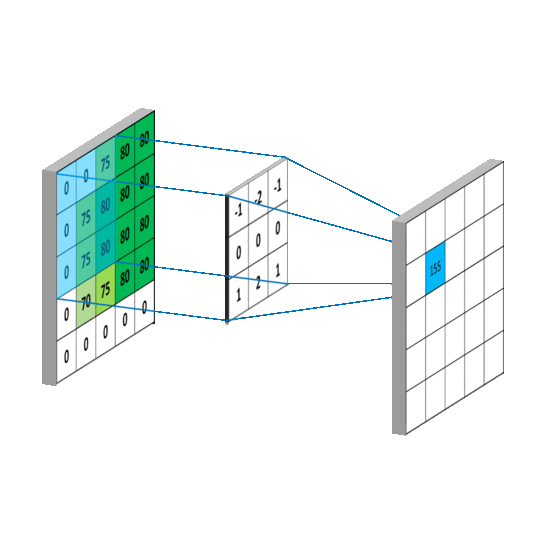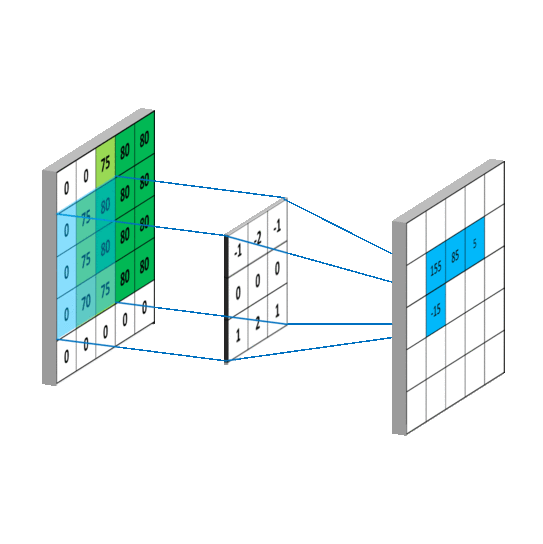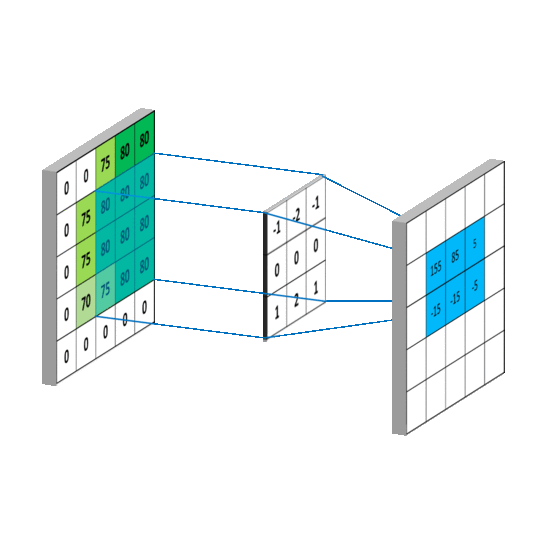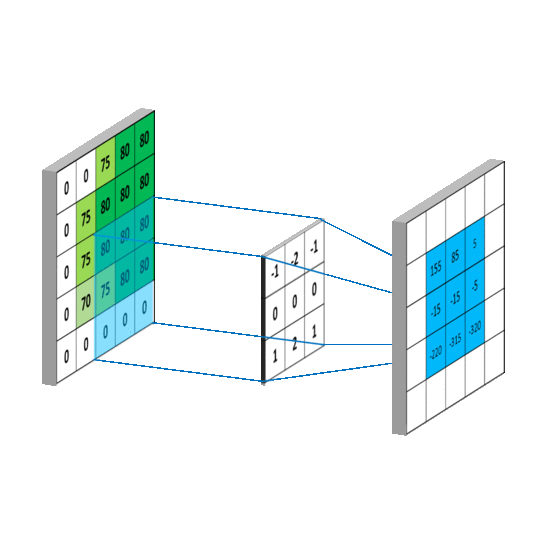
Коротко
Definition
CNN, или свёрточная нейронная сеть, — это нейросетевая архитектура, которая использует свёрточные слои для извлечения локальных пространственных признаков из изображений и других сеточных данных.
CNN особенно часто применяются к изображениям, потому что изображение — это не просто набор чисел, а пространственная структура: соседние пиксели связаны друг с другом.
Главная идея CNN:
- не разворачивать изображение сразу в длинный вектор;
- искать локальные паттерны маленькими фильтрами;
- строить всё более сложные признаки от слоя к слою;
- использовать одни и те же фильтры в разных местах изображения.
Интуиция
Полносвязная сеть плохо подходит для изображений как первая модель, потому что при разворачивании картинки в вектор теряется пространственная структура.
Например, если изображение размером развернуть в вектор, получится больше 150 тысяч входных чисел. Полносвязный слой на таком входе будет иметь очень много параметров и не будет явно учитывать, какие пиксели были рядом.
CNN решает это через свёртки.
Свёрточный фильтр проходит по изображению маленьким окном и ищет локальный паттерн:
- край;
- угол;
- текстуру;
- цветовой переход;
- часть объекта.
Первые слои обычно находят простые признаки. Более глубокие слои собирают из них более сложные паттерны: части объектов, формы и целые визуальные структуры.
Формальное описание
Вход CNN обычно имеет вид тензора:
где:
- — высота изображения;
- — ширина изображения;
- — число каналов.
Для RGB-изображения:
Свёрточный слой применяет набор фильтров к локальным участкам входа. Каждый фильтр создаёт карту признаков, или feature map.
Если фильтров , то выход слоя имеет несколько каналов:
Размеры и зависят от:
- размера фильтра;
- stride;
- padding;
- dilation.
Типичная CNN состоит из блоков:
- Свёрточный слой.
- Нелинейная активация.
- Нормализация, например batch normalization.
- Pooling или downsampling.
- Повторение нескольких таких блоков.
- Классификационная или регрессионная голова.
Входы и выходы
| Компонент | Описание |
|---|---|
| Вход | Изображение или другой тензор с пространственной структурой |
| Типичный формат | |
| Выход для классификации | Вероятности классов или logits |
| Выход для регрессии | Числовое значение |
| Тип обучения | Обычно обучение с учителем |
| Основной строительный блок | Свёрточный слой |
Примеры задач:
- классификация изображений;
- распознавание дефектов на изображениях;
- анализ микроскопических снимков;
- классификация медицинских изображений;
- обработка спектрограмм;
- извлечение признаков из визуальных данных.
Как обучается
CNN обучается через обычный нейросетевой цикл.
- На вход подаётся изображение.
- Свёрточные слои извлекают признаки.
- Последние слои строят предсказание.
- Функция потерь сравнивает предсказание с правильным ответом.
- Через Обратное распространение ошибки считаются градиенты.
- Оптимизатор обновляет веса фильтров и остальных слоёв.
Свёрточные фильтры не задаются вручную. Они обучаются на данных.
Например, в задаче классификации изображений сеть сама учится находить такие фильтры, которые помогают отличать один класс от другого.
Функция потерь
CNN не имеет одной собственной функции потерь. Loss зависит от задачи.
Для классификации чаще всего используют cross-entropy:
где:
- — число классов;
- — истинная метка в one-hot формате;
- — предсказанная вероятность класса.
Для бинарной классификации может использоваться binary cross-entropy.
Для регрессии поверх CNN могут использоваться:
- MSE;
- MAE;
- Huber loss.
Для сегментации используются специальные функции потерь:
- pixel-wise cross-entropy;
- Dice loss;
- IoU loss;
- их комбинации.
Гиперпараметры
Главные гиперпараметры CNN:
| Гиперпараметр | Что контролирует |
|---|---|
| Количество слоёв | Глубину модели |
| Число фильтров | Сколько признаков извлекает слой |
| Размер ядра | Размер локального окна свёртки |
| Stride | Шаг перемещения фильтра |
| Padding | Сохранение или изменение пространственного размера |
| Pooling | Уменьшение пространственного разрешения |
| Activation | Нелинейность, например ReLU |
| Learning rate | Размер шага оптимизации |
| Batch size | Размер мини-батча |
| Weight decay | L2-регуляризация весов |
| Dropout | Случайное отключение активаций |
| Data augmentation | Искусственное разнообразие обучающих изображений |
В современных CNN часто важны не только отдельные гиперпараметры, но и архитектурные решения:
- residual connections;
- batch normalization;
- depthwise separable convolutions;
- bottleneck blocks;
- global average pooling.
Когда использовать
CNN стоит использовать, когда:
- данные имеют пространственную структуру;
- вход — изображение, карта, спектрограмма или похожий тензор;
- важны локальные паттерны;
- один и тот же паттерн может встречаться в разных местах;
- нужно извлекать признаки из изображений;
- полносвязная сеть была бы слишком большой;
- есть достаточно данных или можно использовать pretrained-модель.
CNN особенно полезны в computer vision, где они долго были базовой архитектурой для многих задач.
Когда не использовать
CNN может быть не лучшим выбором, если:
- данные табличные и не имеют пространственной структуры;
- вход — последовательность текста, где важны дальние зависимости;
- данных очень мало и нет pretrained-модели;
- задача требует глобального контекста с самого начала;
- важны отношения между объектами, которые лучше описываются графом;
- трансформерная архитектура уже даёт более сильное решение для конкретной задачи.
Для табличных данных часто лучше начать с линейных моделей, случайного леса или градиентного бустинга. Для текста и длинных последовательностей часто лучше подходят RNN, LSTM или трансформеры.
Метрики оценки
Для классификации изображений используют обычные метрики классификации:
- accuracy;
- precision;
- recall;
- F1-score;
- ROC-AUC для бинарных или multilabel-задач;
- confusion matrix;
- top-k accuracy для многоклассовой классификации.
Подробнее: Метрики качества классификаторов.
Для задач компьютерного зрения могут использоваться и специальные метрики:
- IoU для сегментации;
- Dice score для медицинской сегментации;
- mAP для object detection.
Выбор метрики зависит от задачи: классификация, сегментация, детекция или регрессия.
Типичные ошибки понимания
Ошибка 1. Думать, что CNN нужна только для картинок
CNN чаще всего используют для изображений, но свёртки можно применять и к другим сеточным данным: спектрограммам, временным рядам, сигналам, картам признаков.
Ошибка 2. Считать, что свёртка сама понимает объект целиком
Свёртка видит локальное окно. Глобальное понимание объекта появляется только через много слоёв, увеличение receptive field и объединение признаков.
Ошибка 3. Игнорировать размерности тензоров
В CNN важно следить за формами данных: высотой, шириной, каналами и batch-размером. Ошибки размерностей — частая практическая проблема.
Ошибка 4. Думать, что pooling всегда обязателен
Pooling часто используется, но не является обязательным. Иногда downsampling делают через свёртки со stride больше 1 или вообще сохраняют разрешение.
Ошибка 5. Обучать CNN с нуля на маленьком датасете
CNN может иметь много параметров. Если данных мало, лучше использовать transfer learning, augmentation или более простую модель.
Минимальный пример
import torch
from torch import nn
model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(32, 10),
)
x = torch.randn(8, 3, 64, 64)
logits = model(x)
print(logits.shape)В этом примере вход имеет форму:
То есть:
На выходе получается тензор logits для 10 классов.