Seq2Seq
Коротко
Definition
Seq2Seq — это архитектура для преобразования одной последовательности в другую, обычно через связку encoder-decoder.
Seq2Seq расшифровывается как sequence-to-sequence.
Такие модели принимают на вход последовательность и генерируют другую последовательность.
Примеры:
- машинный перевод: «Как дела?» → “How are you?”;
- суммаризация: длинный текст → короткое резюме;
- диалоговая система: вопрос → ответ;
- распознавание речи: аудиопоследовательность → текст;
- генерация подписи: изображение → текстовое описание.
Главная идея Seq2Seq: входная и выходная последовательности могут иметь разную длину.
Интуиция
Обычная модель классификации выдаёт один ответ: класс или число. Но во многих задачах нужно выдать последовательность.
Например, в переводе одно русское предложение может соответствовать английскому предложению другой длины. Нельзя просто сопоставить первый токен с первым, второй со вторым и так далее.
Seq2Seq решает это через две части:
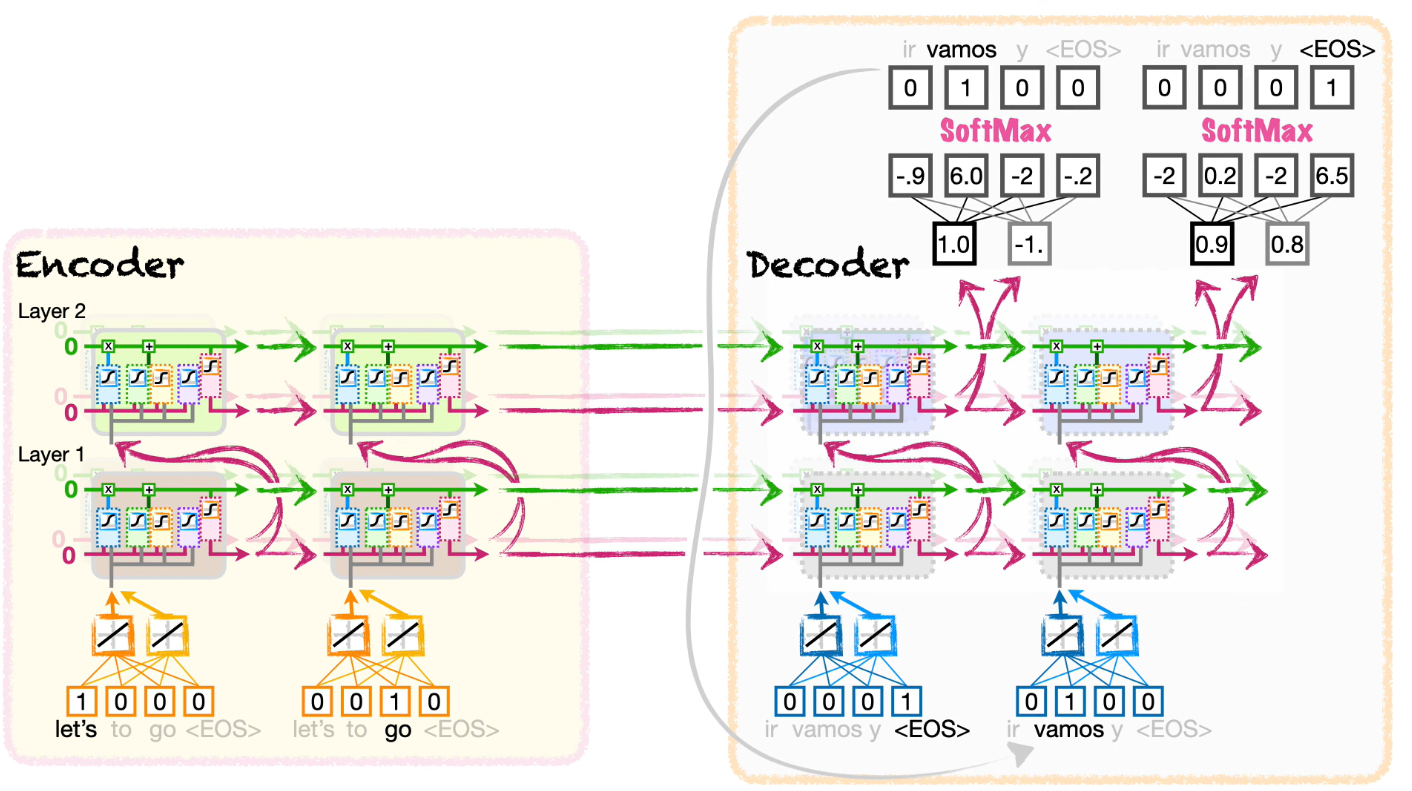
- Encoder читает входную последовательность и строит её представление.
- Decoder по этому представлению генерирует выходную последовательность токен за токеном.
Интуитивно encoder отвечает за понимание входа, а decoder — за порождение ответа.
Формальное описание
Пусть входная последовательность:
А выходная последовательность:
Длины и могут отличаться.
Encoder преобразует входные токены во внутреннее представление:
Decoder генерирует выходную последовательность авторегрессионно:
То есть каждый следующий токен зависит от:
- входной последовательности;
- уже сгенерированных выходных токенов;
- внутреннего состояния decoder.
В классической RNN/LSTM Seq2Seq-архитектуре encoder сжимает вход в context vector. Этот вектор затем используется для инициализации decoder.
В более сильных версиях decoder использует Attention, чтобы обращаться не только к одному context vector, но и ко всем скрытым состояниям encoder.
Входы и выходы
| Компонент | Описание |
|---|---|
| Вход | Последовательность токенов, признаков или временных шагов |
| Выход | Другая последовательность |
| Тип задачи | Sequence modeling |
| Тип обучения | Обычно обучение с учителем |
| Типичная функция потерь | Cross-entropy по токенам |
| Базовые блоки | RNN, LSTM, GRU, Attention, Transformer |
Примеры входов и выходов:
| Задача | Вход | Выход |
|---|---|---|
| Машинный перевод | Предложение на одном языке | Предложение на другом языке |
| Суммаризация | Документ | Краткое резюме |
| Диалог | Реплика пользователя | Ответ модели |
| Speech recognition | Аудио | Текст |
| Text normalization | Неформальный текст | Нормализованный текст |
Как обучается
Seq2Seq обычно обучается на парах:
где — входная последовательность, а — правильная выходная последовательность.
Общий процесс:
- Encoder читает входную последовательность.
- Decoder получает специальный стартовый токен, например
<SOS>или<BOS>. - Decoder предсказывает первый выходной токен.
- На следующем шаге decoder получает предыдущий токен и предсказывает следующий.
- Ошибка считается по всем позициям выходной последовательности.
- Веса encoder и decoder обновляются через обратное распространение ошибки.
При обучении часто используют teacher forcing: decoder получает не свой предыдущий предсказанный токен, а настоящий токен из обучающего примера.
Например, если правильный перевод:
то при обучении decoder может получать:
и учиться предсказывать:
При генерации настоящих токенов уже нет, поэтому decoder использует собственные прошлые предсказания.
Функция потерь
Для текстовых Seq2Seq-задач чаще всего используют cross-entropy по каждому выходному токену.
Если на шаге правильный токен — , а модель предсказала распределение вероятностей , loss:
Итоговая ошибка по последовательности:
Иногда используют среднее по токенам:
Для других типов последовательностей функция потерь может быть другой:
- MSE для числовых временных рядов;
- CTC loss для некоторых speech-задач;
- sequence-level loss для задач, где важна вся последовательность целиком;
- reinforcement learning objective для некоторых задач генерации.
Гиперпараметры
Главные гиперпараметры Seq2Seq:
| Гиперпараметр | Что контролирует |
|---|---|
| Размер словаря | Количество возможных токенов |
| Размер embedding | Размерность токен-векторов |
| Hidden size | Размер скрытых состояний encoder/decoder |
| Количество слоёв | Глубина encoder и decoder |
| Тип блока | RNN, GRU, LSTM, Transformer |
| Dropout | Регуляризация |
| Learning rate | Шаг оптимизации |
| Batch size | Размер мини-батча |
| Teacher forcing ratio | Как часто decoder получает правильный прошлый токен |
| Max sequence length | Максимальная длина генерации |
| Beam size | Ширина beam search при декодировании |
Для качества генерации важны не только параметры обучения, но и стратегия декодирования:
- greedy decoding;
- beam search;
- sampling;
- top-k sampling;
- nucleus sampling.
Когда использовать
Seq2Seq стоит использовать, когда:
- вход и выход являются последовательностями;
- длина входа и выхода может отличаться;
- нужно генерировать текст или другую последовательность;
- задача похожа на перевод, суммаризацию, транскрипцию или диалог;
- важен порядок элементов;
- нужен encoder-decoder подход.
Классические LSTM-based Seq2Seq полезны как учебная архитектура: через них удобно понять, как устроены encoder, decoder, context vector и attention.
Когда не использовать
Классический Seq2Seq на RNN/LSTM может быть не лучшим выбором, если:
- последовательности очень длинные;
- нужен современный state-of-the-art для текста;
- требуется хорошо моделировать дальние зависимости;
- важна высокая параллелизация обучения;
- есть доступ к pretrained transformer-моделям;
- задача не является последовательной.
Для современных NLP-задач чаще используют Трансформер и pretrained language models. Но Seq2Seq остаётся важной базовой идеей, потому что многие transformer-модели тоже имеют encoder-decoder структуру.
Метрики оценки
Метрики зависят от задачи.
Для машинного перевода:
- BLEU;
- chrF;
- COMET.
Для суммаризации:
- ROUGE;
- BERTScore;
- human evaluation.
Для распознавания речи:
- WER;
- CER.
Для задач с токенами:
- token accuracy;
- sequence accuracy;
- perplexity.
Важно: обычная cross-entropy хорошо подходит для обучения, но не всегда идеально отражает качество сгенерированной последовательности для человека.
Типичные ошибки понимания
Ошибка 1. Думать, что Seq2Seq — это только перевод
Машинный перевод — классический пример, но Seq2Seq шире. Это общий подход для преобразования последовательности в последовательность.
Ошибка 2. Путать encoder и decoder
Encoder читает вход. Decoder генерирует выход. Они могут иметь похожие блоки, например LSTM, но выполняют разные роли.
Ошибка 3. Считать context vector достаточным для любой длины
В классическом Seq2Seq один context vector становится bottleneck. Для длинных последовательностей лучше использовать attention.
Ошибка 4. Не различать обучение и генерацию
При обучении decoder часто получает правильный предыдущий токен. При генерации он получает собственный прошлый ответ. Из-за этого ошибки могут накапливаться.
Ошибка 5. Думать, что Seq2Seq всегда рекуррентный
Исторически Seq2Seq часто строили на LSTM или GRU. Но encoder-decoder идея может быть реализована и через трансформеры.
Минимальный пример
import torch
from torch import nn
vocab_size = 1000
embedding_dim = 64
hidden_size = 128
encoder = nn.LSTM(
input_size=embedding_dim,
hidden_size=hidden_size,
batch_first=True,
)
decoder = nn.LSTM(
input_size=embedding_dim,
hidden_size=hidden_size,
batch_first=True,
)
projection = nn.Linear(hidden_size, vocab_size)
source = torch.randn(4, 12, embedding_dim)
target_input = torch.randn(4, 8, embedding_dim)
encoder_outputs, (h, c) = encoder(source)
decoder_outputs, _ = decoder(target_input, (h, c))
logits = projection(decoder_outputs)
print(logits.shape)В этом упрощённом примере encoder получает входную последовательность, а decoder использует финальные состояния encoder как начальное состояние для генерации выходной последовательности.