Обратное распространение ошибки
Коротко
Definition
Обратное распространение ошибки — это алгоритм вычисления градиентов функции потерь по параметрам нейронной сети с помощью последовательного применения правила цепочки от выхода модели к её ранним слоям.
Backpropagation не является отдельной моделью. Это способ эффективно посчитать, как каждый параметр сети влияет на итоговую ошибку.
Главная идея:
- сначала выполнить прямой проход;
- получить предсказание модели;
- посчитать функцию потерь;
- затем идти назад по вычислительному графу;
- применять правило цепочки;
- получить градиенты по всем параметрам;
- передать эти градиенты оптимизатору для обновления весов.
Интуиция
Нейронная сеть — это большая композиция функций.
Например:
Функция потерь зависит от выхода модели, выход зависит от последних слоёв, последние слои зависят от предыдущих и так далее.
Чтобы понять, как изменить вес в раннем слое, нужно ответить на вопрос:
Если немного изменить этот вес, как изменится итоговая ошибка?
Backpropagation отвечает на этот вопрос через производные.
Он распространяет информацию об ошибке назад:
Поэтому алгоритм называется обратным распространением ошибки.
Основные идеи
Правило цепочки
Основа backpropagation — правило цепочки для производных.
Если:
и:
то:
и производная:
То есть влияние на раскладывается на две части:
- как влияет на промежуточную переменную ;
- как влияет на итоговую переменную .
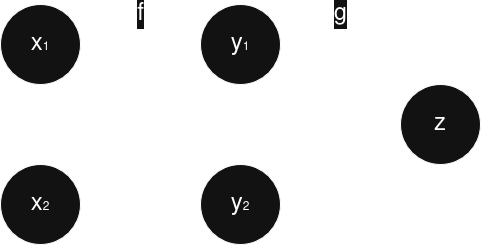
Если переменная влияет на результат через несколько путей, вклады суммируются:
Это важно для нейросетей, потому что вычислительный граф часто имеет разветвления.
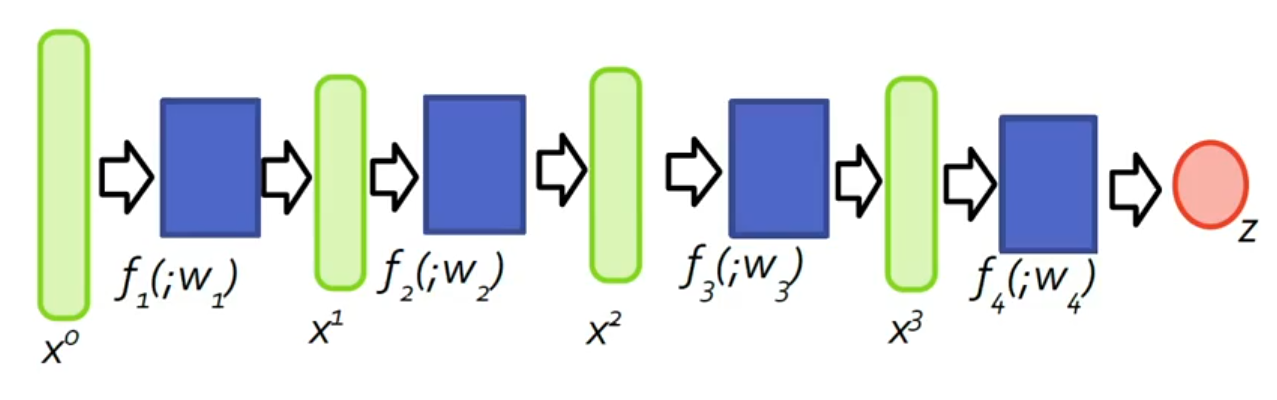
Прямой и обратный проход
Обучение нейросети обычно состоит из двух проходов.
Forward pass
На прямом проходе сеть вычисляет предсказание:
Затем считается ошибка:
Во время forward pass сохраняются промежуточные значения: входы слоёв, активации и выходы операций. Они нужны для вычисления производных на обратном проходе.
Backward pass
На обратном проходе вычисляются градиенты:
для всех обучаемых параметров .
Градиенты показывают, как изменение каждого параметра повлияет на функцию потерь.
После этого оптимизатор обновляет параметры, например по правилу градиентного спуска:
где — learning rate.
Пример для последовательности слоёв
Пусть модель — это композиция функций:
Функция потерь:
Нужно найти производные:
Для последнего слоя цепочка короткая:
Для более раннего слоя цепочка длиннее:
Для самых ранних слоёв нужно пройти через ещё больше промежуточных операций.
Пример с активациями
Пусть есть простая сеть:
Функция потерь:
Градиент по последнему весу:
Градиент по весу второго слоя:
Градиент по весу первого слоя:
Чем раньше слой, тем длиннее цепочка производных.
От чего зависит величина градиента
Градиент раннего слоя зависит от произведения многих множителей:
Поэтому градиент зависит от трёх групп факторов:
- Конечная ошибка модели.
- Производные всех операций выше данного слоя.
- Вход и локальная операция данного слоя.
Отсюда возникает проблема затухающих и взрывающихся градиентов.
Если много производных меньше 1, их произведение может стать почти нулевым. Тогда ранние слои почти не обучаются.
Если много производных больше 1, их произведение может стать очень большим. Тогда обучение становится нестабильным.
Подробнее: Затухание градиента.
Когда использовать
Backpropagation используется почти всегда, когда обучается нейронная сеть через градиентную оптимизацию.
Типичные случаи:
- полносвязные сети;
- CNN;
- LSTM;
- трансформеры;
- autoencoder;
- GAN;
- модели для классификации;
- модели для регрессии;
- языковые модели.
Backpropagation нужен, когда:
- модель дифференцируема;
- есть функция потерь;
- параметры нужно обновлять по градиенту;
- обучение выполняется через optimizer, например SGD, Adam или AdamW.
Когда не использовать
Backpropagation не подходит напрямую, если:
- операции в модели недифференцируемы;
- нет функции потерь;
- параметры не обучаются градиентным методом;
- задача решается алгоритмом без обучаемых весов;
- требуется оптимизация дискретных решений без дифференцируемого приближения.
Например, классические деревья решений, случайный лес, k-means и DBSCAN не обучаются через backpropagation в обычном виде.
Если в модели есть недифференцируемые части, иногда используют:
- surrogate loss;
- reinforcement learning;
- straight-through estimator;
- эволюционные алгоритмы;
- численную оптимизацию без градиентов.
Минимальный пример
import torch
from torch import nn
x = torch.tensor([ [1.0, 2.0] ])
y = torch.tensor([ [1.0] ])
model = nn.Sequential(
nn.Linear(2, 4),
nn.ReLU(),
nn.Linear(4, 1),
)
loss_fn = nn.MSELoss()
prediction = model(x)
loss = loss_fn(prediction, y)
loss.backward()
for name, parameter in model.named_parameters():
print(name, parameter.grad)В этом примере:
prediction = model(x)выполняет forward pass;loss_fn(prediction, y)считает ошибку;loss.backward()запускает backpropagation;parameter.gradсодержит градиенты по параметрам.
После этого оптимизатор мог бы обновить параметры модели.
Связанные понятия
Что знать перед этим
- Кросс-энтропия
- Производная
- Правило цепочки