Рекуррентный слой
Коротко
Definition
Рекуррентный слой — это архитектурный блок нейронной сети для обработки последовательностей, в котором состояние на текущем шаге зависит от текущего входа и состояния на предыдущем шаге.
Рекуррентный слой нужен для данных, где важен порядок элементов: текстов, временных рядов, сигналов, событийных историй и других последовательностей.
Главная идея: слой обрабатывает последовательность шаг за шагом и переносит информацию из прошлого через скрытое состояние.
Зачем нужен
Обычный Полносвязный слой получает входной вектор и сразу строит выходной вектор. Он не хранит память о предыдущих шагах.
Рекуррентный слой добавляет память:
- на шаге он получает текущий вход ;
- берёт скрытое состояние с предыдущего шага ;
- строит новое скрытое состояние .
Это позволяет модели учитывать контекст.
Например:
- в тексте значение слова зависит от предыдущих слов;
- во временном ряду текущее значение зависит от прошлых значений;
- в истории действий пользователя следующее действие зависит от предыдущих действий;
- в сигнале важна динамика, а не только отдельное измерение.
Как работает
Базовая формула выхода рекуррентного слоя на шаге :
где:
- — вход на текущем шаге;
- — скрытое состояние с предыдущего шага;
- — новое скрытое состояние;
- — матрица весов для текущего входа;
- — матрица весов для предыдущего скрытого состояния;
- — вектор смещений;
- — функция активации.
Смысл двух частей:
- обрабатывает текущий вход;
- переносит информацию из прошлого.
Итоговое состояние можно использовать двумя способами:
- как выход на текущем шаге;
- как память, которая передаётся на следующий шаг.
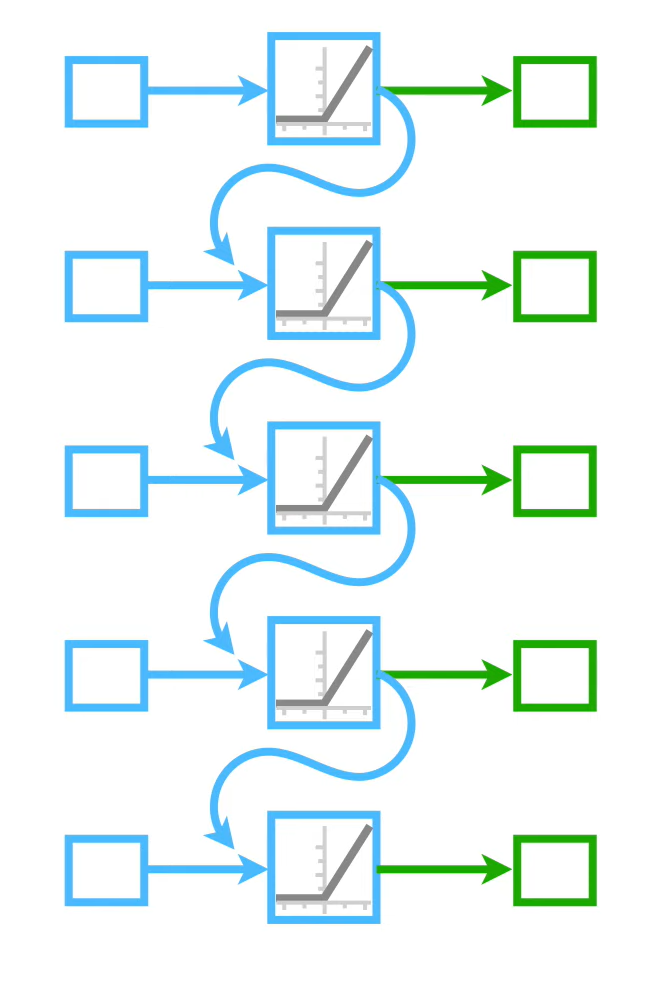
Разворачивание во времени
Рекуррентный слой можно представить как один и тот же блок, применяемый много раз к разным элементам последовательности.
Для последовательности:
слой последовательно вычисляет:
и так далее до .
Важно: веса и одни и те же на всех шагах. Это называется shared weights.
Обучаемые параметры
В процессе обучения изменяются:
- матрица весов для входа ;
- матрица весов между шагами ;
- вектор смещений ;
- дополнительные параметры, если используется более сложная рекуррентная ячейка.
Для базового RNN-слоя число параметров зависит от:
- размерности входа;
- размерности скрытого состояния;
- наличия bias.
Если вход имеет размерность , а скрытое состояние — , то:
Как обучается
Рекуррентные слои обучаются с помощью обратного распространения ошибки, но с учётом временной структуры. Такой вариант называется backpropagation through time.
Идея:
- Модель проходит последовательность вперёд и сохраняет скрытые состояния.
- Ошибка считается на одном или нескольких шагах.
- Градиент распространяется назад через шаги последовательности.
- Обновляются общие веса , и .
Проблема в том, что при длинных последовательностях градиент проходит через много шагов. Из-за этого могут возникать:
- затухающие градиенты;
- взрывающиеся градиенты;
- трудности с обучением долгих зависимостей.
Именно поэтому на практике часто используют не простую RNN, а более устойчивые варианты, например LSTM.
Гиперпараметры
Основные гиперпараметры рекуррентного слоя:
- размер скрытого состояния;
- число рекуррентных слоёв;
- тип рекуррентной ячейки;
- направление обработки: однонаправленная или bidirectional;
- dropout между слоями;
- длина последовательности или максимальная длина;
- способ использования выхода: последний шаг, все шаги или pooling по шагам.
Размер скрытого состояния определяет, сколько информации слой может хранить в памяти. Чем он больше, тем выразительнее модель, но тем выше риск переобучения и вычислительная стоимость.
Где используется
Рекуррентные слои используются для последовательных данных:
- классификация текста;
- прогнозирование временных рядов;
- обработка сигналов;
- распознавание речи;
- sequence labeling;
- машинный перевод;
- генерация текста;
- анализ истории действий пользователя.
Исторически рекуррентные слои были базовым инструментом для NLP и временных рядов. Сейчас во многих задачах их вытеснили трансформеры, но RNN и LSTM всё ещё полезны для небольших моделей, потоковых данных и задач с ограниченными ресурсами.
Связанные архитектуры
Рекуррентный слой связан с несколькими архитектурами:
- LSTM — рекуррентная архитектура с механизмами управления памятью;
- GRU — упрощённый вариант gated recurrent unit;
- Seq2Seq — архитектура encoder-decoder для преобразования последовательностей;
- Attention — механизм выбора важных элементов последовательности;
- Трансформер — архитектура, которая во многих задачах заменила RNN за счёт self-attention.
В простых RNN память передаётся одним скрытым состоянием. В LSTM дополнительно используется cell state, который помогает хранить информацию на длинных интервалах.
Типичные ошибки понимания
Думать, что RNN хорошо помнит всё прошлое
Теоретически рекуррентная сеть может передавать информацию через много шагов. На практике простая RNN часто плохо обучается на длинных зависимостях из-за затухания градиента.
Путать скрытое состояние и выход
В простых RNN скрытое состояние часто одновременно является выходом слоя. Но в более сложных архитектурах выход и внутреннее состояние могут различаться.
Забывать, что веса общие для всех шагов
Рекуррентный слой не имеет отдельные веса для каждого шага последовательности. Один и тот же набор весов применяется повторно на всех шагах.
Использовать случайное train-test split для временных рядов
Если последовательность связана со временем, случайное перемешивание может привести к data leakage. Для временных рядов часто нужно обучаться на прошлом и проверяться на будущем.
Считать RNN всегда лучшим выбором для последовательностей
Рекуррентные слои хорошо подходят для некоторых последовательных задач, но не всегда являются оптимальными. Для длинных текстов и многих NLP-задач чаще используют трансформеры.
Минимальный пример
Пусть есть последовательность из трёх элементов:
Рекуррентный слой обрабатывает её так:
Если задача — классификация всей последовательности, можно взять последнее скрытое состояние и подать его в Полносвязный слой:
Например, для классификации отзыва модель читает слова по порядку, обновляет скрытое состояние и в конце решает, положительный отзыв или отрицательный.
Практические замечания
При работе с рекуррентными слоями важно учитывать:
- Длины последовательностей.
- Padding и masks.
- Правильный порядок элементов.
- Способ разделения train и test.
- Риск затухания градиента.
- Нужен ли bidirectional layer.
- Использовать последний hidden state или все hidden states.
- Достаточен ли простой RNN или лучше использовать LSTM.
В учебных задачах простой рекуррентный слой полезен для понимания идеи памяти в нейросетях. В реальных задачах часто стоит начинать с LSTM, GRU или transformer-based модели.