LSTM
Коротко
Definition
LSTM — это рекуррентный архитектурный блок, который помогает нейросети хранить и обновлять информацию на длинных последовательностях через специальное состояние памяти и обучаемые gates.
LSTM расшифровывается как Long Short-Term Memory.
Главная идея:
- обычная RNN быстро забывает раннюю информацию;
- градиенты при обучении могут затухать или взрываться;
- LSTM добавляет отдельное состояние памяти ;
- gates управляют тем, что забыть, что добавить и что вывести наружу.
LSTM долго был одной из ключевых архитектур для текста, временных рядов и других последовательностей до широкого распространения трансформеров.
Зачем нужен
Обычный рекуррентный слой обрабатывает последовательность шаг за шагом. На каждом шаге он получает текущий вход и скрытое состояние с прошлого шага.
Проблема в том, что при длинных последовательностях ранняя информация часто теряется. Например, в длинном предложении слово в начале может быть важно для слова в конце, но обычной RNN трудно сохранить эту связь.
LSTM решает эту проблему через отдельную долгосрочную память:
Эта память передаётся по времени более напрямую и обновляется аддитивно. Поэтому ей легче сохранять информацию на многих шагах.
LSTM нужен, чтобы:
- лучше работать с длинными зависимостями;
- уменьшить проблему затухающих градиентов;
- управлять памятью последовательности;
- выбирать, какую информацию забыть, сохранить и вывести.
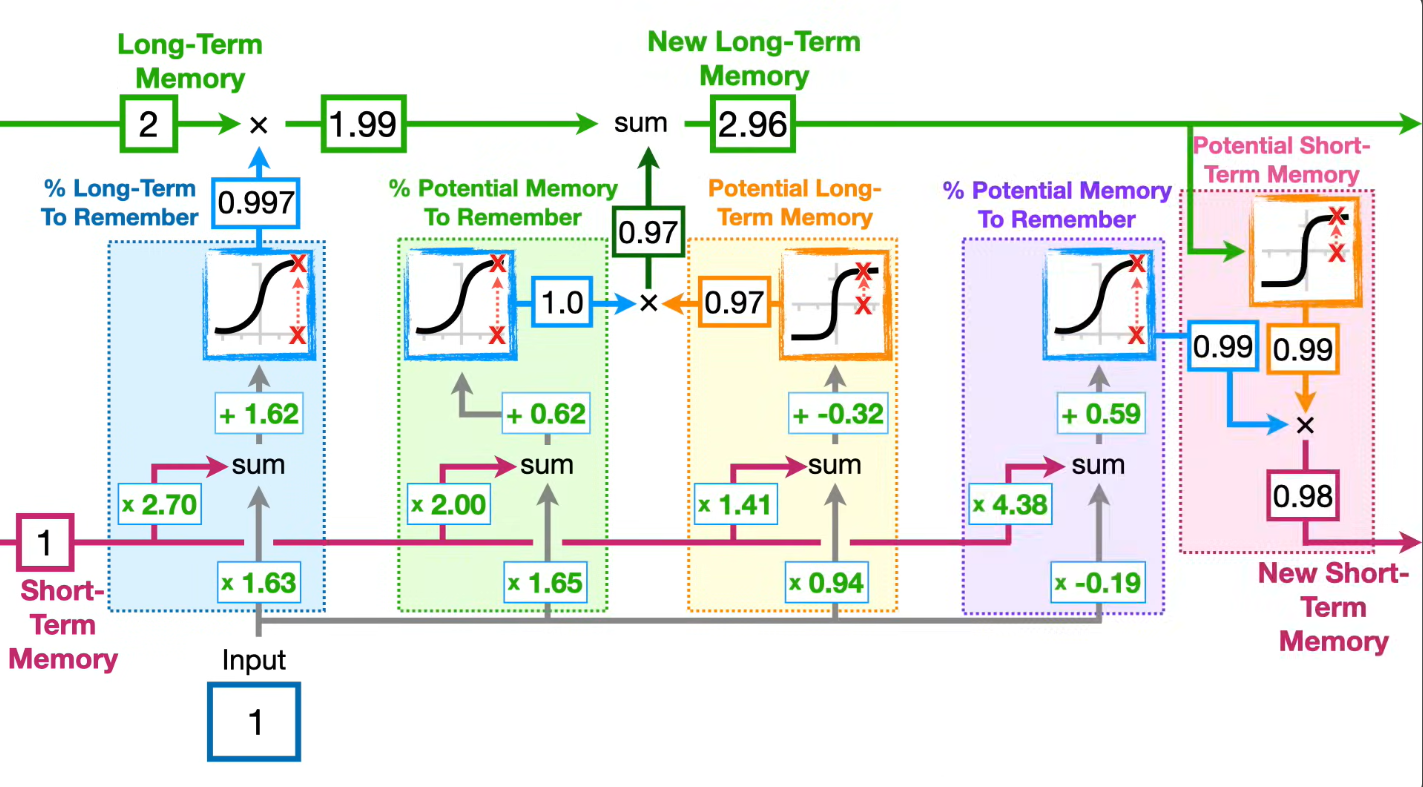
Как работает
В LSTM есть два основных состояния:
- — hidden state, или краткосрочное состояние;
- — cell state, или долгосрочная память.
На каждом шаге времени блок получает:
- текущий вход ;
- прошлое скрытое состояние ;
- прошлое состояние памяти .
Затем LSTM вычисляет несколько gates.
Forget gate
Forget gate решает, какую часть старой памяти сохранить:
Если значение близко к 0, информация забывается. Если близко к 1, информация сохраняется.
Input gate
Input gate решает, какую новую информацию добавить в память:
Кандидат новой памяти:
Обновление cell state
Долгосрочная память обновляется так:
Здесь видно главное отличие LSTM: память обновляется аддитивно, а не только через повторное нелинейное преобразование.
Output gate
Output gate решает, какую часть памяти вывести в hidden state:
Итоговое скрытое состояние:
Где используется
LSTM используют для последовательных данных.
Типичные применения:
| Область | Примеры |
|---|---|
| Текст | классификация текста, языковое моделирование, машинный перевод |
| Временные ряды | прогнозирование, анализ сенсорных данных, финансы |
| Аудио | распознавание речи, обработка сигналов |
| Биоданные | последовательности ДНК, белковые последовательности |
| Seq2Seq | encoder-decoder модели до трансформеров |
Сейчас во многих NLP-задачах LSTM заменены трансформерами, но они всё ещё полезны для небольших данных, временных рядов и задач, где рекуррентная обработка естественна.
Связанные архитектуры
Обычная RNN
Обычная RNN имеет только скрытое состояние . Она проще, но хуже сохраняет дальние зависимости.
GRU
GRU — упрощённая альтернатива LSTM. В ней меньше gates и нет отдельного cell state в таком же виде. GRU часто быстрее, но может быть менее гибкой.
Seq2Seq
В классических Seq2Seq-архитектурах LSTM часто использовалась как encoder и decoder.
Attention
Attention частично решает проблему длинных зависимостей иначе: он позволяет модели обращаться к разным позициям входной последовательности напрямую, а не только через рекуррентную память.
Transformer
Трансформер почти полностью отказался от рекуррентности и заменил её self-attention. Поэтому в современных языковых моделях LSTM используется гораздо реже.
Типичные ошибки понимания
Ошибка 1. Думать, что LSTM полностью решает проблему длинного контекста
LSTM лучше обычной RNN, но не даёт бесконечной памяти. На очень длинных последовательностях информация всё равно может теряться.
Ошибка 2. Путать hidden state и cell state
— это выход блока на текущем шаге. — это внутренняя долгосрочная память. Они связаны, но выполняют разные роли.
Ошибка 3. Считать gates ручными правилами
Forget gate, input gate и output gate не задаются вручную. Их веса обучаются через Обратное распространение ошибки.
Ошибка 4. Думать, что LSTM всегда лучше трансформера
Для многих задач с текстом трансформеры сильнее. Но LSTM может быть проще, дешевле и удобнее на небольших последовательных данных.
Ошибка 5. Игнорировать порядок данных
LSTM обрабатывает последовательность по шагам, поэтому порядок элементов важен. Если перемешать временные шаги или токены, смысл модели нарушится.
Минимальный пример
import torch
from torch import nn
batch_size = 4
seq_len = 10
input_size = 8
hidden_size = 16
x = torch.randn(batch_size, seq_len, input_size)
lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
batch_first=True,
)
outputs, (h_n, c_n) = lstm(x)
print(outputs.shape)
print(h_n.shape)
print(c_n.shape)В этом примере:
outputsсодержит hidden states для всех шагов последовательности;h_nсодержит последнее hidden state;c_nсодержит последнее cell state.