Случайный лес
Коротко
Definition
Случайный лес — это ансамблевая модель, которая строит много деревьев решений на случайных подвыборках данных и признаков, а затем объединяет их предсказания.
Случайный лес, или Random Forest, используется для классификации и регрессии.
Главная идея:
- одно дерево решений может легко переобучиться;
- много разных деревьев ошибаются по-разному;
- если объединить их ответы, итоговая модель становится устойчивее.
Для классификации случайный лес обычно выбирает класс большинством голосов деревьев. Для регрессии он усредняет числовые предсказания деревьев.
Интуиция
Одиночное дерево решений похоже на одного эксперта, который задаёт последовательность вопросов к данным. Такой эксперт может слишком хорошо запомнить обучающую выборку и ошибаться на новых данных.
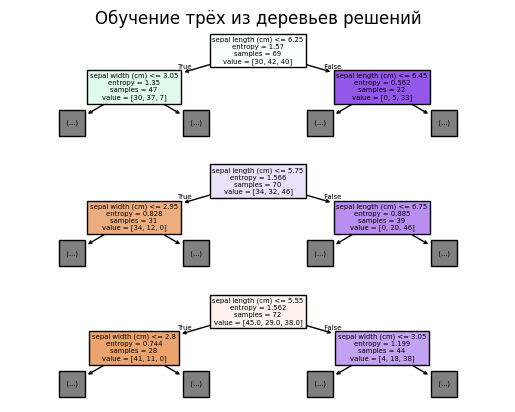
Случайный лес строит много деревьев. Каждое дерево видит немного разные данные и разные признаки. Поэтому деревья получаются не одинаковыми.
Затем модель объединяет их ответы:
- в классификации — голосованием;
- в регрессии — усреднением.
Интуитивно это похоже на коллектив экспертов: отдельный эксперт может ошибиться, но усреднённое решение группы часто стабильнее.
Формальное описание
Случайный лес состоит из набора деревьев решений:
где — количество деревьев.
Каждое дерево обучается на bootstrap-выборке: из исходного датасета случайно выбираются объекты с возвращением.
Кроме того, при построении каждого узла дерево рассматривает не все признаки, а только случайное подмножество признаков. Это делает деревья менее похожими друг на друга.
Для классификации итоговое предсказание:
То есть выбирается класс, за который проголосовало больше всего деревьев.
Для регрессии итоговое предсказание:
То есть берётся среднее предсказание всех деревьев.
Входы и выходы
| Компонент | Классификация | Регрессия |
|---|---|---|
| Вход | Вектор признаков объекта | Вектор признаков объекта |
| Выход | Метка класса | Числовое значение |
| Тип обучения | Обучение с учителем | Обучение с учителем |
| Базовая модель | Дерево решений | Дерево решений |
| Тип ансамбля | Bagging | Bagging |
Примеры задач:
- классификация клиентов;
- предсказание цены;
- оценка риска;
- классификация материалов по устойчивости;
- предсказание числового свойства материала;
- baseline для табличных данных.
Как обучается
Случайный лес обучается как ансамбль деревьев.
Алгоритм:
- Задать количество деревьев .
- Для каждого дерева создать bootstrap-выборку из исходных данных.
- Построить дерево решений на этой выборке.
- При каждом разбиении узла рассматривать только случайное подмножество признаков.
- Повторить процесс для всех деревьев.
- Объединять предсказания деревьев при инференсе.
Два источника случайности:
- случайный выбор объектов для каждого дерева;
- случайный выбор признаков при разбиениях.
Именно эта случайность снижает корреляцию между деревьями. Чем менее похожи ошибки отдельных деревьев, тем полезнее их объединение.
Дополнительно случайный лес может использовать out-of-bag оценку. Так как каждое дерево обучается только на bootstrap-выборке, часть объектов не попадает в обучение конкретного дерева. Эти объекты можно использовать для внутренней оценки качества.
Функция потерь
У случайного леса нет одной глобальной дифференцируемой функции потерь, как у линейной или логистической регрессии.
Каждое отдельное дерево строится жадно: на каждом шаге выбирается разбиение, которое сильнее всего улучшает критерий качества узла.
Для классификации часто используются:
| Критерий | Идея |
|---|---|
| Gini impurity | Насколько классы перемешаны в узле |
| Entropy | Насколько неопределённо распределение классов в узле |
| Log loss | Вероятностный критерий для классификации |
Индекс Джини:
Энтропия:
Для регрессии часто используются:
| Критерий | Идея |
|---|---|
| Squared error | Уменьшать дисперсию целевой переменной в листьях |
| Absolute error | Делать разбиения более устойчивыми к выбросам |
| Poisson | Для счётных неотрицательных целевых переменных |
Важно: случайный лес оптимизирует качество отдельных разбиений внутри деревьев, а не одну общую функцию ансамбля напрямую.
Гиперпараметры
Главные гиперпараметры случайного леса:
| Гиперпараметр | Что контролирует |
|---|---|
n_estimators | Количество деревьев |
max_depth | Максимальная глубина деревьев |
max_features | Сколько признаков рассматривать при разбиении |
min_samples_split | Минимум объектов для разделения узла |
min_samples_leaf | Минимум объектов в листе |
bootstrap | Использовать ли bootstrap-выборки |
oob_score | Считать ли out-of-bag оценку |
class_weight | Веса классов при дисбалансе |
criterion | Критерий качества разбиения |
Наиболее важные параметры:
n_estimators: больше деревьев обычно стабильнее, но медленнее;max_depth: ограничивает сложность деревьев;max_features: влияет на разнообразие деревьев;min_samples_leaf: помогает бороться с переобучением.
Когда использовать
Случайный лес стоит использовать, когда:
- данные табличные;
- нужна сильная модель без сложной настройки;
- есть нелинейные зависимости;
- есть взаимодействия между признаками;
- важна устойчивость к переобучению по сравнению с одним деревом;
- нужен хороший baseline для классификации или регрессии;
- хочется оценить важность признаков.
Случайный лес часто хорошо работает «из коробки» и требует меньше тонкой настройки, чем многие другие модели.
Когда не использовать
Случайный лес может быть не лучшим выбором, если:
- нужна очень компактная и быстрая модель;
- критична интерпретируемость каждого решения;
- данных очень много, и обучение становится тяжёлым;
- нужна хорошая экстраполяция за пределы диапазона train-данных;
- задача лучше решается градиентным бустингом;
- признаки очень разреженные и высокоразмерные, например bag-of-words для текстов.
Случайный лес плохо экстраполирует в регрессии: он обычно предсказывает значения в диапазоне, похожем на обучающие листья, а не продолжает тренд далеко за пределы обучающих данных.
Метрики оценки
Для классификации используются:
- accuracy;
- precision;
- recall;
- F1-score;
- ROC-AUC;
- PR-AUC;
- confusion matrix.
Подробнее: Метрики качества классификаторов и ROC-кривая.
Для регрессии используются:
- MAE;
- MSE;
- RMSE;
- ;
- MAPE.
Подробнее: Метрики качества регрессоров.
Также для случайного леса можно смотреть:
- out-of-bag score;
- feature importance;
- permutation importance;
- качество на validation или test-наборе.
Типичные ошибки понимания
Ошибка 1. Думать, что случайный лес не переобучается
Случайный лес обычно устойчивее одиночного дерева, но всё равно может переобучаться. Особенно если деревья очень глубокие, данных мало или признаки содержат утечки.
Ошибка 2. Считать feature importance доказательством причинности
Важность признака показывает, что модель использовала этот признак для предсказаний. Это не доказывает причинную связь.
Ошибка 3. Игнорировать дисбаланс классов
Если один класс встречается намного чаще другого, случайный лес может хорошо выглядеть по accuracy, но плохо находить редкий класс.
Ошибка 4. Ожидать хорошей экстраполяции
В регрессии случайный лес плохо продолжает линейные или физические тренды за пределы обучающих данных. Для экстраполяции иногда лучше подходят линейные модели, физически мотивированные признаки или специализированные модели.
Ошибка 5. Считать случайный лес полностью интерпретируемым
Отдельное дерево можно понять визуально, но лес из сотен деревьев уже не является простой интерпретируемой моделью.
Минимальный пример
import numpy as np
from sklearn.ensemble import RandomForestClassifier
X = np.array([
[0.1, 1.0],
[0.2, 1.1],
[1.0, 0.1],
[1.1, 0.2],
[0.9, 0.3],
[0.3, 0.9],
])
y = np.array([0, 0, 1, 1, 1, 0])
model = RandomForestClassifier(
n_estimators=100,
max_depth=3,
random_state=42,
)
model.fit(X, y)
sample = np.array([ [0.8, 0.2] ])
prediction = model.predict(sample)
print(prediction)В этом примере случайный лес строит много деревьев решений и выбирает класс по большинству голосов.