Логистическая регрессия
Коротко
Definition
Логистическая регрессия — линейный вероятностный классификатор, который оценивает вероятность принадлежности объекта к классу через сигмоиду от линейной комбинации признаков.
Несмотря на название, логистическая регрессия решает задачу классификации, а не регрессии. В базовом случае она предсказывает вероятность положительного класса:
где — логистическая функция, или сигмоида:
Интуиция
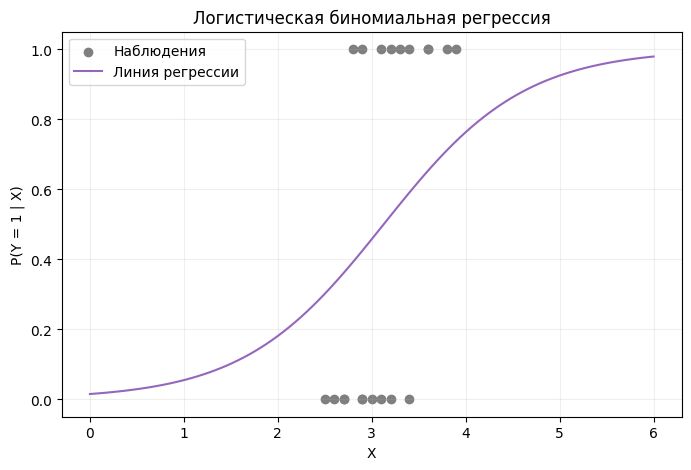
Логистическую регрессию можно понимать как линейную модель, поверх которой поставили ограничитель вероятности.
Сначала модель считает линейный score:
Затем score преобразуется сигмоидой в число от 0 до 1. Это число интерпретируется как вероятность положительного класса.
Если вероятность выше выбранного порога, например , объект относят к классу 1; если ниже — к классу 0.
Главная идея:
признаки → линейная оценка → вероятность → класс
Формальное описание
Для бинарной классификации модель имеет вид:
где:
- — вектор признаков объекта;
- — веса признаков;
- — свободный член;
- — предсказанная вероятность положительного класса.
Для получения класса используется порог:
Обычно , но при несбалансированных классах или разных ценах ошибок порог можно менять.
Для многоклассовой классификации используют два основных подхода:
- One-vs-rest: для каждого класса обучается отдельный бинарный классификатор.
- Multinomial / softmax: модель сразу оценивает вероятности всех классов через softmax.
Входы и выходы
Входы:
- матрица признаков ;
- целевая переменная :
- бинарная: ;
- многоклассовая: .
Выходы:
- вероятность класса;
- предсказанная метка класса;
- коэффициенты модели , которые можно интерпретировать как вклад признаков в логит.
Для бинарной классификации модель возвращает вероятность положительного класса. Для многоклассовой классификации — вектор вероятностей по классам.
Как обучается
Логистическая регрессия обучается через максимизацию правдоподобия наблюдаемых меток.
Для каждого объекта модель предсказывает вероятность правильного класса. Затем параметры и подбираются так, чтобы правильные классы получали как можно более высокие вероятности.
На практике вместо максимизации правдоподобия обычно минимизируют отрицательное логарифмическое правдоподобие, то есть кросс-энтропию.
Общий цикл обучения:
- Инициализировать веса и смещение .
- Посчитать логиты .
- Преобразовать логиты в вероятности через сигмоиду или softmax.
- Посчитать функцию потерь.
- Обновить параметры оптимизационным методом.
- Повторять до сходимости или достижения лимита итераций.
Функция потерь
Для бинарной классификации используется бинарная кросс-энтропия:
Для набора из объектов:
Если , модель штрафуется за маленькую вероятность положительного класса. Если , модель штрафуется за большую вероятность положительного класса.
Для многоклассовой классификации используется многоклассовая кросс-энтропия:
где — индикатор того, что объект принадлежит классу .
Гиперпараметры
Основные гиперпараметры:
- тип регуляризации: L1, L2, elastic net или без регуляризации;
- сила регуляризации;
- алгоритм оптимизации;
- максимальное число итераций;
- критерий остановки;
- веса классов при дисбалансе;
- стратегия многоклассовой классификации;
- наличие или отсутствие свободного члена ;
- порог классификации после получения вероятности.
Важная практическая деталь: сила регуляризации влияет на сложность модели. Слишком сильная регуляризация может привести к недообучению, слишком слабая — к переобучению.
Когда использовать
Логистическую регрессию стоит использовать, когда:
- нужна простая и интерпретируемая baseline-модель;
- задача — бинарная или многоклассовая классификация;
- данные преимущественно табличные;
- связь между признаками и логитом класса примерно линейная;
- важно получать вероятности, а не только метки классов;
- нужно быстро проверить, есть ли в признаках полезный сигнал.
Логистическая регрессия часто хороша как первая модель перед более сложными алгоритмами вроде SVM, дерева решений, случайного леса или градиентного бустинга.
Когда не использовать
Логистическая регрессия может быть плохим выбором, если:
- граница между классами сильно нелинейная;
- важны сложные взаимодействия признаков, которые явно не заданы;
- признаки плохо подготовлены;
- классы сильно несбалансированы, а порог и веса классов не настроены;
- данные имеют сложную структуру: изображения, тексты, графы, последовательности.
В таких случаях могут лучше подойти деревья, ансамбли, kernel-SVM или нейронные сети.
Метрики оценки
Для оценки логистической регрессии используют обычные метрики качества классификаторов:
- accuracy;
- precision;
- recall;
- F1-score;
- ROC-AUC;
- PR-AUC;
- confusion matrix.
Если модель используется как вероятностный классификатор, важно смотреть не только на качество классов после порога, но и на качество вероятностей.
Для анализа порога полезна ROC-кривая.
Типичные ошибки понимания
-
Думать, что логистическая регрессия решает регрессию.
Название историческое: модель предсказывает вероятность класса, а не непрерывную целевую переменную. -
Считать выход модели готовым классом.
Сначала модель выдаёт вероятность, а класс появляется только после выбора порога. -
Забывать про масштабирование признаков.
Для регуляризованной логистической регрессии признаки разного масштаба могут искажать вклад коэффициентов. -
Интерпретировать коэффициенты без учёта подготовки данных.
Коэффициенты зависят от масштаба, кодирования категорий и корреляций между признаками. -
Считать порог 0.5 универсальным.
При дисбалансе классов или разной цене ошибок порог нужно подбирать под задачу.
Минимальный пример
Пусть объект описывается одним признаком , а модель имеет параметры и .
Для объекта :
Если порог равен , модель предсказывает класс 1.
Минимальный пример на Python:
from sklearn.linear_model import LogisticRegression
X = [
[0.1, 1.2],
[1.3, 0.4],
[1.1, 0.8],
[0.2, 1.0],
]
y = [0, 1, 1, 0]
model = LogisticRegression()
model.fit(X, y)
proba = model.predict_proba([ [0.8, 0.7] ])
pred = model.predict([ [0.8, 0.7] ])
print(proba)
print(pred)